[Paper Review] HeteroLLM: Accelerating Large Language Model Inference on Mobile SoCs with Heterogeneous AI Accelerators
해당 논문(링크)은 2025년 1월에 arxiv에 올라온 논문으로, 교수님께서 공유해주신 Awesome-On-Device-AI-Systems에 소개되어 있어서 읽어보게 되었다. 이 글에서는 단순히 해당 논문의 내용과 주장을 정리하기 때문에, 해당 내용이 사실인지는 별도의 검증과 조사가 필요하다.
Abstract
Privacy와 response latency 등의 측면을 개선하기 위해, 현재 ai를 mobile system 등에서 on-device로 돌리는 시도가 이루어지고 있다. 현재의 mobile SoC(System on Chip)에서는 이에 따른 computational demand를 만족시키기 위해, GPU, NPU 등 다양한 ai accelerator를 포함하고 있다. 하지만 현존하는 design들은 단일 ai accelerator에 대한 것으로, computation 및 memory bandwidth 측면에서 이런 heterogeneous processor들을 잘 고려해서 최적화하지는 못한다.
이에 따라 논문에서는 우선 mobile SoC의 heterogeneous processor에 대한 성능적 특징을 분석한다. 이후 저자는 해당 관찰을 통해 1. prefill phase와 decoding phase 각각에서의 요구사항에 따른 partition strategy와, 2. mobile SoC에서의 fast synchronization 기법을 활용하여, layer-level과 tensor-level 모두에 대해서 heterogeneous execution을 지원하는 inference engine인 HeteroLLM을 제시한다.
Introduction
해당 연구의 필요성
앞에서 언급한 것처럼 현재 ai를 스마트폰과 같은 mobile system에서 돌리려는 시도가 이루어지고 있고, 이에 따라 SoC 제조사들은 GPU, NPU와 같이 matrix/vector multiplication에서 이점을 가지는 다양한 ai accelerator들을 칩 안에 통합시켜왔다. 하지만 heterogeneous processor들을 활용하는 inference engine에 대한 선행 연구들은 아래와 같은 이유로 현재의 mobile platform에 적합하지 않다.
GPU와 NPU를 위한 기존의 synchronization 기법은 LLM inference에 대한 overhead가 크다. 특히 각 kernel의 실행 시간이 수백 ms로 특히 짧은 decoding phase에서 overhead가 더욱 커진다.
NPU는 GPU보다 대체로 높은 성능을 보인다. 예를 들어, Qualcomm 8 Gen 3에서 GPU는 실제로 2.8 TFLOPS를 보이는데, NPU는 10 TFLOPS를 보인다.
기존 engine 중에 효율적인 GPU-NPU parallelism, 또는 tensor-level의 parallelism을 구현한 것은 존재하지 않는다.
아래 표와 같이 기존의 inference engine들은 NPU를 활용하지 않거나, NPU를 활용하지만 int 연산을 활용하여 속도를 확보한 대신 accuracy 하락이 존재한다.
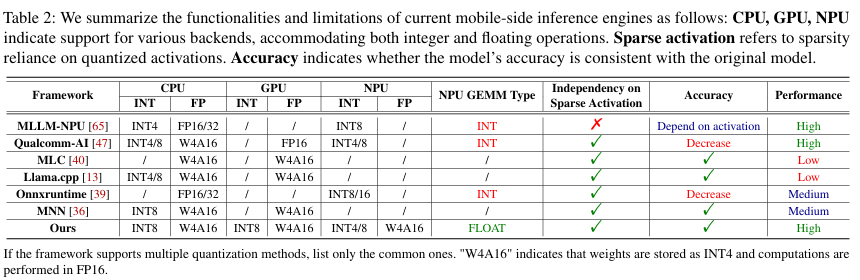
이에 따라 heterogeneous processor들, 특히 NPU를 고려한 efficient inference engine은 여전히 중요한 과제로 남아있다.
Mobile SoC의 특징
Mobile SoC에 대한 분석 결과, 그 하드웨어 architecture적인 특징으로는 아래와 같은 것들이 있다.
NPU 성능은 tensor-sensitive하다.
최적의 조건인 경우에 NPU는 tensor 연산에 대해 GPU보다 높은 성능을 보인다. 하지만 tensor의 order, size, shape 등이 NPU의 하드웨어 architecture에 적합하지 않다면 그 성능은 GPU 수준 또는 그 이하로 떨어진다.
NPU의 static computation graph.
현재의 mobile NPU는 static computation graph만을 지원하는데, 이는 LLM의 dynamic한 workload와 호환되지 않는다. 하지만 런타임에 이를 계산하는 것은 overhead가 크다.
Computation Graph는 모델의 연산과 데이터의 흐름을 나타낸 graph이다. Dynamic Graph는 연산이 dynamic하게 결정될 수 있는 graph로, 임의의 sequence length를 가지는 input을 처리할 수 있다. 반면 Static Graph는 실행 전에 모든 연산 구조가 고정되어야 하는 graph로, 고정된 sequence length의 input만을 처리할 수 있다. training 시에는 dynamic graph가 더 유리하지만, inference에서는 매번 동일한 연산을 반복하므로 static graph를 활용하는 것이 다양한 최적화 기법을 적용하기에 유리하다고 한다.
computation graph와 관련된 더 자세한 내용은 ‘Computation Graph Optimization 1부 - Computation Graph, 최적화의 출발점’에서 확인할 수 있다.
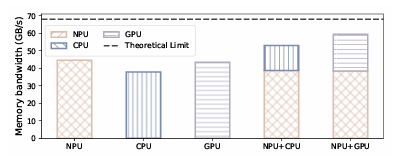
단일 processor의 memory bandwidth restriction.
단일 processor만 사용하는 경우 SoC의 전체 memory bandwidth를 충분히 활용하기 어렵다.
이런 성능적 특징을 고려했을 때, mobile SoC에서 NPU의 성능이 저하되는 특정 상황에 이를 GPU로 보완하는 GPU-NPU parallelism 기법이 유효할 수 있다.
HeteroLLM
이에 따라 논문에서 제시하는 inference engine인 HeteroLLM은 mobile SoC에서의 heterogeneous processing을 지원한다. HeteroLLM에서 CPU는 synchronization 및 GPU kernel scheduling 등을 수행하고, NPU는 primary computing unit으로 기능하며, GPU는 NPU의 lower bound를 개선하기 위한 secondary computing unit으로 동작한다. 또한 layer-level과 tensor-level 모두에 대해 GPU-NPU parallelism을 구현하기 위해 HeteroLLM에서는 아래의 기법을 활용한다.
- tensor-level heterogeneous execution을 위해 prefill phase와 decoding phase 각각에 대해 다른 tensor partition 전략을 활용한다.
- kernel waiting time을 기반으로 한 fast synchronization 기법을 활용한다.
- hardware profiler와 runtime decider를 활용하는 tensor partition solver를 활용한다.
저자는 HeteroLLM을 CPU/GPU를 활용하는 SOTA LLM inference engine인 PPL을 기반으로 구현했고, NPU에 대한 처리는 Qualcomm의 QNN을 활용해 구현했다. 또한 이를 Arm CPU/GPU/NPU를 모두 포함하는 SoC인 Qualcomm 8 Gen 3에서 돌렸다고 한다.
결과적으로 HeteroLLM은 billion-scale mobile LLM에 대해 prefill에서 float 연산을 사용하여 성능 하락 없이 가속화하였고, prefill phase와 decoding phase 모두에서 성능 향상을 보였다.
Background & Related Work
LLM Inference
LLM inference는 prefill phase와 decoding phase로 나뉜다.
Prefill Phase
input 전체를 한 번에 처리하여 첫 번째 token을 생성하는 phase. 이에 따라 matrix-matrix multiplication이 수행되고, computation intensive하다(computation이 병목이다.).
Decoding Phase
autoregressive로 sequential하게 한 번에 하나의 token을 생성하는 phase. 이에 따라 matrix-vector multiplication이 수행되고, memory-intensive하다(memory bandwidth가 병목이다.).
mobile에서의 LLM inference의 latency는 TTFT(Time to First Token)와 TPOT(Time per Output Token)으로 구분될 수 있는데, 각각 prefill phase와 decoding phase의 속도에 의해 정해진다.
Mobile-side Heterogeneous SoC
앞에서 언급한 것처럼 privacy와 security, latency 등의 이유로 데이터를 cloud service로 전송하는 대신 LLM을 local device에서 돌리려는 시도가 이루어지고 있다. 이에 따라 주요 제조사들은 CPU, GPU, NPU를 포함하는 heterogeneous SoC를 개발하고 있다. (모바일 SoC 성능 순위 - Nanoreview) 또한 mobile-side에서 이런 processor들은 하나의 physical memory를 공유하도록 구현되는 경우가 많다.
Mobile-side Inference Engine
mobile-side inference engine으로는 ONNX Runtime, Llama.cpp, MNN, PPL 등 여러 가지가 있고, 이는 대체로 ONNX format으로 입력을 받아 runtime graph 생성을 위한 optimization을 수행하는 식으로 동작한다. 또한 mobile accelerator들을 CPU, GPU, NPU 등의 백엔드로 추상화하고, processor의 instruction set과 programming language를 활용해 대응되는 low-level operator를 구현한다.
그러나 기존의 inference engine들은 heterogeneous processor들을 활용하지만 accuracy 하락이 존재하거나, tensor-level의 granularity로는 활용하지 못하는 등의 한계가 존재한다. 또한 GPU를 활용하는 engine은 많지만 아직 GPU-NPU parallelism을 잘 구현하진 못했다.
Performance Characteristic
design을 살펴보기 전에 우선 각 processor의 architecture적인 특성을 알아보자.
GPU Characteristics
SIMT instruction, on-chip shared memory, SM(Streaming Multiprocessor)을 활용한다는 점 등에서 mobile GPU는 desktop GPU와 동일하다. 하지만 system memory와 별개로 독립된 memory를 활용하는 desktop GPU와는 달리, mobile GPU는 system memory에 통합되어 있는 UMA(Unified Memory Address Space)를 활용한다.
하지만 OpenCL 등 desktop GPU를 상정하는 framework들은 이런 구조를 반영하고 있지 않아 mobile GPU에 대한 redundancy가 존재한다. 예를 들어, mobile GPU는 UMA를 활용하므로 CPU memory와 GPU memory 사이의 데이터 데이터 전송이 불필요하다.
mobile GPU의 주요 특징들로는 아래와 같은 것들이 있다.
Linear Performance
연산하는 tensor의 크기에 따른 GPU의 성능(TFLOPS)은 아래의 그래프와 같다. tensor size가 작을 때 TFLOPS가 linear하게 증가하므로, 연산이 memory-bound이다. 이후 특정 threshold 이후에는 TFLOPS가 더 이상 증가하지 않으며 연산이 computation-bound이다.
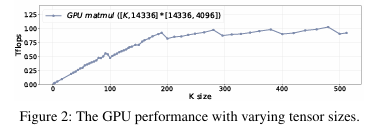
High-cost Synchronization
GPU에 대한 synchronization은 비용이 높은데, 이는 1. 현재의 GPU framework는 mobile GPU에 대해서도 desktop GPU에서와 같이 API를 호출하도록 구현되어 있고 이에 따라 data size에 관계없이 400 ms 정도의 latency가 발생하기 때문이다. 또한, 2. GPU는 기본적으로 asynchronous model로 설계되어 queue에 kernel을 저장해 두고 연산하는데, synchronization을 적용하면 queue가 완전히 비워질 때까지 기다렸다가, 이후 kernel submission이 수행되기 때문에 50~100 ms의 추가적인 latency가 발생하게 된다.
NPU Characteristics
NPU에서 가장 중요한 component는 matrix computation unit(ex. systolic array)로, 아래의 그림은 가장 기본적인 systolic array의 구조이다. NPU의 연산 과정으로는, computation 이전에 우선 PE(Processing Element)에 weight가 preload되고, 이후 weight stall(고정) 상태로 input/activation에 대한 계산이 수행된다. 이후 최종 결과는 on-chip SRAM에 저장되거나 다음 systolic array unit에 전달된다. 이런 과정을 통해 NPU는 weight/activation에 대한 load/store 연산과 cycle 수를 줄여, 특정 상황에서 GPU보다 효과적으로 연산을 수행한다.
참고로, Systolic Array의 기본적인 동작은 Systolic Array를 보면 쉽게 이해할 수 있다.
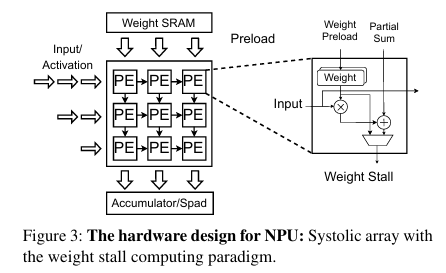
위와 같은 architecture에 따라, NPU의 성능은 아래와 같이 3가지 특징을 가진다.
Stage performance
NPU의 hardware computing array(ex. systolic arary)의 크기가 고정되어 있기 때문에, matrix multiplication을 수행해야 하는 tensor의 크기가 computing unit의 크기와 align되지 않으면 해당 unit이 inefficient하게 활용되게 된다. computing unit들을 최적으로 활용하려면 compiler가 tensor를 computing unit 크기에 맞도록 잘 나눠줘야 하고, tensor를 쪼갠 뒤 남는 부분이 생길 경우 연산을 위해 padding을 추가한다.
이에 따라 tensor의 크기에 의해 NPU 성능이 아래의 그래프와 같이 결정된다. 이런 misalignment result를 Stage Performance라고 한다.
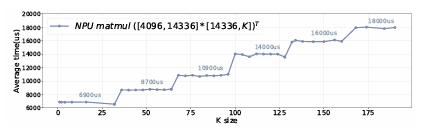
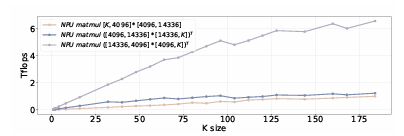
Order-sensitive performance
$M \times N$ matrix와 $N \times K$ matrix의 multiplication, 그리고 $K \times N$ matrix와 $N \times M$ matrix의 multiplication은 모두 실제 연산량이 $2MNK$로 동일하다. 하지만 NPU에서는 아래의 그래프와 같이 weight tensor가 클수록 성능 저하가 발생한다(오른쪽 matrix가 weight). 이는 weight tensor가 클수록 단일 computing unit으로 처리하는 대신, computing unit에 값을 load/store하는 것을 반복하며 연산해야 하기 때문이다.
NPU는 weight stall에 따른 load/store 연산을 줄여 성능을 향상시키기 때문에 이런 경우 성능이 떨어지는 것인데, 이를 Order-sensitive Performace라고 한다.
Shape-sensitive performance
NPU의 성능은 input tensor의 shape에 의해서도 결정된다. input tensor의 row보다 column이 클수록 성능이 저하되는데, 이는 matrix multiplication이 수행되므로, output tensor의 shape이 고정되어 있을 때 column의 크기가 weight tensor의 크기에 영향을 미치기 때문이다(오른쪽 matrix가 weight).
SoC Memory Bandwidth
Qualcomm Snapdragon 8 Gen 3에서 실험한 결과, 아래 그래프와 같이 decoding phase에서 단일 processor만 사용하는 경우 SoC의 최대 memory bandwidth를 충분히 활용하지 못한다. 즉, NPU-GPU parallelism으로 memory bandwidht를 더욱 활용함으로써 성능 향상을 기대할 수 있다.
Design
앞에서 언급한 것처럼 HeteroLLM에서 CPU는 synchronization, GPU kernel scheduling, non-compute intensive task를 처리하는 control plane으로 활용한다. CPU는 LLM task를 처리하기에 적합하지 않고, 다른 application도 처리해야 하므로 모든 power를 사용하지 않는 것으로 했다. 반편 NPU는 특정 상황을 제외하면 LLM task에 대해 GPU보다 성능이 뛰어나므로 primary computing unit으로, GPU는 NPU의 lower bound를 보완하는 secondary computing unit으로 활용한다.
HeteroLLM에서는 GPU-NPU parallelism에 따른 heterogeneous execution을 아래와 같이 layer-level과 tensor-level로 구현한다.
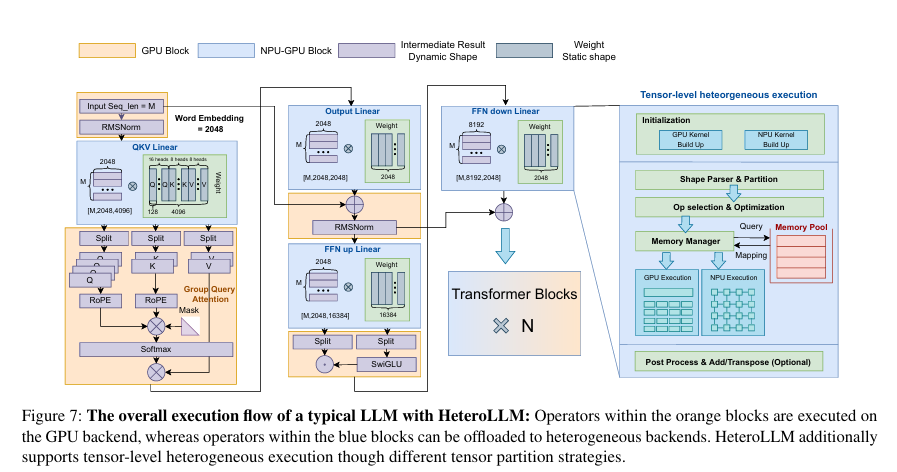
Layer-level apporach에서는 1. 각 연산을 가장 적절한 backend(GPU or NPU)에 할당한다. 예를 들어, Matrix multiplication은 NPU에, RMSNorm과 SwiGLU는 GPU에 할당한다. 그리고 2. 전형적인 LLM에서는 input에 비해 weight가 크므로 transpose하여 오른쪽 matrix(weight 위치)에 input(더 작은 쪽)이 오도록 한다.
Tensor-level approach에서는 backend에 따른 partition 전략을 활용하고, solver를 사용하여 최적의 partition solution을 결정하도록 한다.
또한 이 두 approach 모두에 대해 새로운 fast synchronization 기법을 적용하여 GPU, NPU에서의 synchronization overhead를 줄인다.
전반적인 실행 흐름은 아래 그림과 같다.
Tensor Partition Strategy
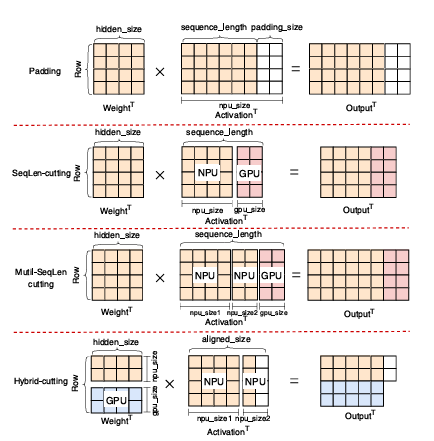
HeteroLLM에서 활용하는 partition strategy는 아래와 같은 것들이 있다. 이는 1. tensor shape에 따른 NPU 성능 저하, 2. 고비용의 static computation graph, 3. SoC memory bandwidth를 고려한 기법들이다.
Partition during Prefill Phase
prefill phase에서 적용 가능한 partition strategy로는 이런 것들이 있다. 이 전략들은 prefill phase가 computation-bound임을 고려하여, computation power를 확보하기 위한 것으로 이해할 수 있다.
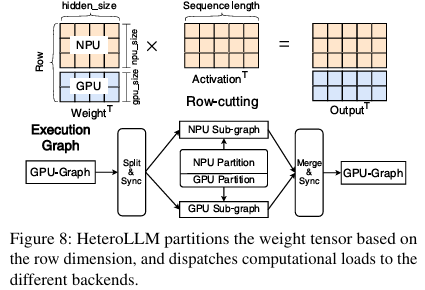
Row-cutting
앞에서 언급한 것처럼 activation-weight multiplication은 전치해서 $W^T A^T$로 연산하는 것으로 한다. 이 경우 만약 sequence length($A^T$의 column)가 짧아지면 stage performance에 의해 NPU의 computational resource를 충분히 활용하지 못한다. 또한 FFN-down은 dimension을 줄이는 layer이므로 $W^T$는 row에 비해 column이 더 큰 matrix이므로, shape-sensitive performance에 의해 성능 저하가 발생한다.
이런 경우 등에서 NPU의 성능은 GPU 수준 또는 그 이하로 떨어지게 되는데, 이때 첫 번째 matrix($W^T$)를 row dimension에 대해 partition하는 Row-cutting을 적용하여 일부는 NPU에서, 다른 일부는 GPU에서 연산하도록 한다. 또한 partition 함에 따라 다른 layer의 연산 이전에 GPU/NPU 각각에 의해 연산되는 모든 부분이 완료되었음을 보장하기 위해 synchronizaiton point를 명시적으로 설정한다.
즉, NPU와 GPU에 연산을 나눠 실행하도록 하는데, NPU의 성능에 따라 GPU 활용 정도를 조정한다.
Sequence-length cutting
현재의 mobile NPU에서는 static graph execution만을 지원한다. 즉, kernel initialization 시에 tensor의 size와 shape이 결정될 수 있어야 하는데, 이를 runtime에 매번 계산하는 것은 overhead가 크다. 반면 GPU는 다양한 tensor shape을 처리할 수 있는 여러 kernel implementation을 지원하므로, 임의의 shape을 가지는 tensor를 dynamic하게 처리할 수 있다.
NPU에서 dynamic input shape을 처리할 수 있도록 하는 기본적인 방법은, predefined tensor shape의 집합을 미리 정의해 두고 input tensor에 padding을 붙여 해당 shape으로 맞춘 뒤 연산하는 것이다. 하지만 이 경우 padding에 의한 추가적인 computational overhead가 발생한다. 예를 들어, sequence length가 130인 경우 256에 맞추기 위해 padding을 126만큼 추가하고 연산해야 한다.
이에 따라 논문에서는 아래 그림과 같이 Sequence-length cutting을 적용하여, NPU에서는 fixed-size tensor를 연산하도록 하고, GPU에서는 dynamic-shape tensor를 연산하도록 한다.
Multi-sequence-lenght cutting
linear performance에서 확인했듯이, GPU에서도 sequence length가 threshold를 넘어가면 computation이 병목이 된다.
이에 따라 위 그림과 같이 input tensor를 한 번이 아니라 여러 번 predefined shape으로 쪼개는 Multi-sequence-length cutting을 활용할 수 있다. 이 경우 여러 개의 predefined shape으로 tensor를 쪼개 TPU에서 연산하도록 하고, 임의의 shape을 가지는 마지막 tensor를 GPU에서 연산하도록 한다.
Hybrid-cutting
위 그림과 같이 row-cutting과 sequence-length cutting을 함께 활용하는 Hybrid-cutting도 가능하다. 이 경우 row-cutting에 의해 나눠진 GPU 연산 부분에서는 단순히 연산하면 되고, NPU 연산 부분에서는 padding을 추가해 연산한다.
Partition during Decoding Phase
prefill phase와는 달리 decoding phase는 memory bandwidth가 병목이다. 앞서 본 관찰에서 알 수 있듯이, 단일 processor를 활용하는 경우 SoC의 전체 memory bandwidth를 충분히 활용하지 못하므로 NPU와 GPU를 모두 사용하도록 한다. 이때 input token의 sequence length는 기본적으로 1(물론 speculative decoding 등을 사용하면 n)로 고정되므로, NPU computation graph를 predefine할 수 있다.
이에 따라 NPU computation graph에 대한 overhead는 고려할 필요가 없고, row-cutting을 적용해 TPU/GPU에 의한 memory bandwidth 활용을 최대화한다. 여기에서의 row-cutting은 prefill에서와 같이 computation 측면에서의 최적화라기보단, memory bandwidth 측면의 최적화로서 기능한다.
또한 아래에서 설명할 partition solver를 사용하여 최적의 partition 정도를 계산한다.
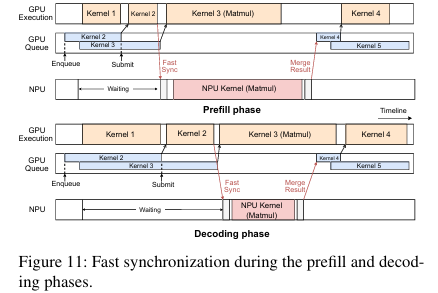
Fast Synchronization
GPU-NPU parallelism은 실행 시간을 줄이지만 synchronization에 따른 overhead가 추가로 발생할 수 있다. 특히 단일 연산의 실행 시간이 짧은 decoding phase에 그 overhead가 두드러진다. 이에 따라 HeteroLLM은 아래의 두 가지 synchronization 기법을 활용한다.
mobile SoC에서는 unified memory를 사용하므로 추가적인 data transfer가 필요하지 않다. 그래서 transfomer의 각 연산에 대한 input/output tensor들을 저장하기 위한 dedicated memory pool을 reserve해 활용한다. LLM의 각 layer는 동일한 decoder block 구조를 사용하므로 이 memory를 재사용될 수 있다.
LLM은 대체로 동일한 연산을 수행하므로 각 layer에 대한 waiting time을 예측할 수 있다. synchronization 대상인 thread는 해당 waiting time만큼 sleep했다가 polling mechanism(실행해도 되는지 반복 확인하는 방식)을 통해 다시 실행하도록 한다. 이때 mobile SoC의 usleep이 가지는 granularity는 80~100 ms 수준으로 정확한 synchronization에는 적합하지 않다. 이에 따라 thread의 sleep이 끝나면 CPU core를 활용해 output tensor가 준비되었는지 flag bit(output tensor가 준비되면 set되도록 구현했다.)에 대한 polling으로 확인한다.
이런 synchronization은 아래 그림과 같이 prefill phase와 decoding phase에서 각각 다른 양상을 보인다. prefill phase에서는 NPU가 computaiton 측면에서 dominant하고 GPU는 덜 활용되므로, 다음 GPU kerenl에 대한 submission은 NPU 연산을 기다려야 한다. 이에 따른 submission overhead가 존재하기는 하는데, 10 ms 정도로 무시할 수 있다고 한다. 반면 decoding phase에서는 GPU가 dominant하고, GPU submission overhead도 적다.
Putting It All Together
앞에서 설명한 design들을 종합적으로 활용하기 위해, HeteroLLM은 성능을 측정하는 profiler와, partition 전략을 결정하는 solver를 활용하여 아래와 같은 과정으로 동작한다.
- solver가 predefined sequence length들을 활용하여 모델이 사용하는 tensor shape을 확인한다.
- solver는 profiler를 사용해 최적의 partition 전략을 결정하고, 실제로 partition한다.
- 해당 partition에 따라 각 backend(GPU/TPU)에 대한 computation graph가 생성된다.
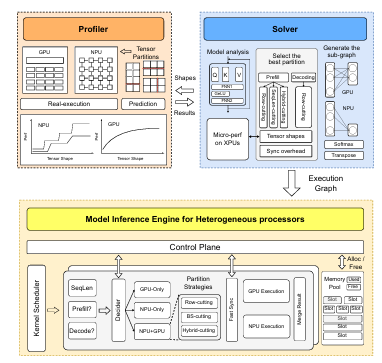
이제 profiler와 sovler의 동작에 대해 더 구체적으로 알아보자.
Performance Profiler
profiler는 각 heterogeneous processor에 대한 성능을 측정하는 부분으로, profiler는 real-execution mode와 prediction mode가 존재한다.
real-execution mode는 다양한 shape의 tensor에 대해 target 연산을 실제로 실행해 성능을 측정하는 방식이다. 당연하게도 time-consuming하지만 실제 값을 얻을 수 있고, offline으로 우선 처리될 수 있다. 또한 NPU의 stage performance에 따라 search space를 효과적으로 줄일 수 있다.
prediction mode는 target 연산의 성능을 예측하는 방식이다. tree regression같은 전통적인 ML 기법을 사용해 다양한 shape의 tensor에 대해 성능을 예측할 수 있다. 또한 GPU는 NPU에 비해 더 안정적이고, shape에 비교적 independent한 성능을 보이므로 성능 예측이 더 용이하다.
Tensor Partition Solver
solver는 profiler의 결과를 활용해 GPU-only vs. NPU-only vs. GPU-NPU parallelism 중 뭐가 최적인지 판단한다. GPU-NPU parallelism을 활용하는 경우 모든 가능한 partition 방법들을 비교하며 어떤 partition 전략을 활용할 것인지도 결정한다. 이에 따라 solver가 최적화해야 하는 전체 실행 시간에 대한 objective function은 아래와 같이 계산된다. 이때 GPU와 NPU를 함께 사용하는 경우 kernel submission(sync)과 activation transfer(copy) 또한 고려함을 알 수 있다.
논문에서는 별도의 설명이 나와있지 않지만, 여기에서의 GPU-only vs. NPU-only vs. GPU-NPU는 matrix multiplication 연산에서의 processor 활용을 말하는 것 같다. 이에 따라 NPU-only의 경우에도 SwiGLU, norm 부분 등은 GPU가 연산하므로 sync, copy cost가 발생한다.

Inference Engine
위의 과정은 offline으로 수행되고, 이후 inference 시에도 control plane(CPU)는 kernel이 GPU-only vs. NPU-only vs. GPU-NPU parallelism 중 어떻게 실행될지를 phase와 sequence lenght를 고려해서 결정한다. 또한 fast synchronization을 적용하고, GPU/NPU kernel에 의해 사용되는 shared memroy pool도 관리한다.
Evaluation
저자는 HeteroLLM을 SOTA mobile-side inference engine인 PPL(CPU/GPU)을 기반으로 구현했고, QNN-NPU(NPU) library를 사용해 NPU에 대한 부분을 구현했다. 또한 이렇게 구현한 inference engine을 Qualcomm 8 Gen 3에서 돌렸다고 한다.
HeteroLLM이 가지는 의의는 accuracy 손실 없이 빠른 속도를 확보했다는 것이므로, 이를 실험적으로 증명하는 데에 목적이 있다. 이에 따라 model quantization으로는 W4A16(weight-only)을 적용하여 float computation과 int4 weight storage를 사용했다. 또한 accuracy 손실이 없는 inference engine들과의 비교를 위해 llama.cpp(CPU), MLC(GPU), MNN(GPU) 등에 대해 실험했고, prefill phase에서 layer-level 기법만 활용하는 경우 각각 25.1×, 7.27×, 3.18×배의 성능 향상을, tensor-level 기법까지 활용하는 경우 40%만큼의 추가적인 성능 향상을 보였다. 또한 decoding phase에서 tensor-level 기법까지 활용하는 경우 최대 23.4%만큼의 성능 향상을 보였다고 한다.
Prefill Performance
mobile-side NPU에서는 static graph execution만을 지원하므로, input token의 sequence length가 NPU에 대해 align되어 있는지에 따라 성능 비교를 수행했다.
Aligned Sequence Length
아래의 그래프와 같이 여러 모델과 sequence length에 대해 비교를 수행했다. layer-level 기법만을 적용한 HeteroLLM, 그리고 tensor-level 기법까지 적용한 HeteroLLM을 사용해 실험한 결과, 모든 경우에서 높은 성능을 보임을 확인했다.
GPU만 활용한 것보다 layer-level 기법만을 적용한 HeteroLLM의 성능이 더 높으므로, GPU 대신 NPU의 활용도를 높인 것이 computation을 많이 요구하는 연산(ex. matrix multiplication)에 대해 대부분의 경우 더 적절했음을 알 수 있다. 또한 tensor-level 기법까지 적용한 HeteroLLM의 성능이 layer level 기법만을 적용했을 때보다 더 높으므로, 특정 shape의 tensor에 대해 GPU가 NPU의 성능 저하를 보완했음을 알 수 있다.
그래프에는 나와있지 않지만 다른 NPU를 활용하는 다른 inference engine보다 HeteroLLM의 성능 또한 더 좋다고 한다. 예를 들어, sequence length 256에 대해 token/s가 2배정도 차이가 난다. 이런 기존의 NPU 활용 inference engine들은 단순히 int computation을 위해 사용했다고 한다.
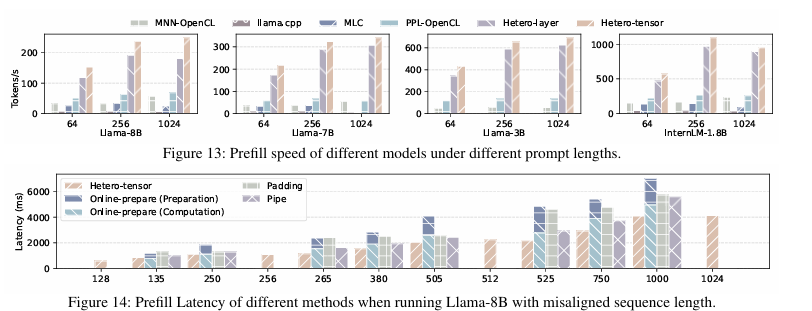
Misaligned Sequence Length
아래 그래프와 같이 여러 sequence length에 대해 비교를 수행했다. mobile NPU가 static computation graph만을 지원하므로, online-prepare, padding, pipe, 그리고 논문에서 제시한 방식인 tensor-level 기법까지 적용한 HeteroLLM을 비교했다. tensor-level 기법까지 적용한 HeteroLLM의 성능이 가장 뛰어남을 확인했다.
여기에서 Online-prepare는 각 input sequence length에 대해 매번 새로운 graph를 생성하는 방식, Padding은 특정 standard size(ex. 128, 256)의 graph를 미리 생성해 두고, input에 padding을 추가하여 해당 size에 맞추는 방식, Pipe는 앞에서 설명한 multi-sequence-length cutting 전략을 사용해 standard size를 넘어가는 부분(margin)을 더 작은 부분으로 나눠서 계산하고 남는 부분은 padding을 추가하는 방식이다.
이 결과에 따라 매번 graph를 계산하는 것의 overhead가 크다는 점, 단순 padding을 사용하면 step-wise하게 latency가 증가한다는 점, 남는 부분을 standard size에 맞는 더 작은 부분으로 나눴을 때 latency가 더 적다는 점 등을 알 수 있다.
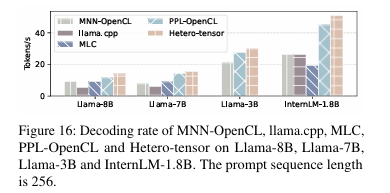
Decoding Performance
아래 그래프와 같이 여러 모델에 대해 decoding speed에 대한 비교를 수행했다. HeteroLLM은 decoding phase에 NPU와 GPU를 동시에 사용하는 유일한 engine이고, 실험 결과 Hetero-tensor의 memory bandwidth가 NPU 또는 GPU를 단독으로 활용할 때보다 높기 때문에 성능 또한 높은 것으로 판단된다고 한다.
decoding phase에서는 input sequence length가 짧아서 NPU 성능이 대체로 GPU보다 낮다. 이에 따라 layer-level 기법만을 활용하는 HeteroLLM의 경우 solver가 항상 NPU 대신 GPU만을 선택하여 PPL과 유사한 성능이 나온다고 한다.
즉, decoding phase에서 개별 성능만 놓고 보면 GPU가 NPU보다 좋은데, tensor-level partition에 의해 GPU와 TPU를 모두 사용하면 더 큰 memory bandwidth를 더 활용하므로 성능이 높다.
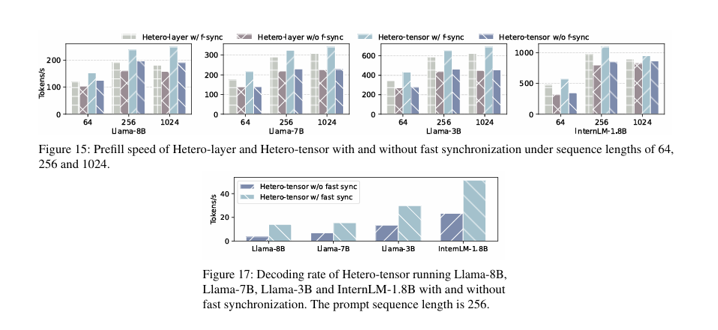
Effect of Fast Synchronization
아래의 그래프와 같이 prefill phase, decoding phase 모두에서 fast synchronization 적용 시 성능이 높아졌다.
이때 prefill phase에서는 tensor-level partition이 수행됨에 따라 tensor-level HeteroLLM이 layer-level HeteroLLM보다 더 sensitive했다. 또한 decoding phase에서 각 kernel의 실행 시간이 더 짧으므로 prefill phase보다 sensitive했다.
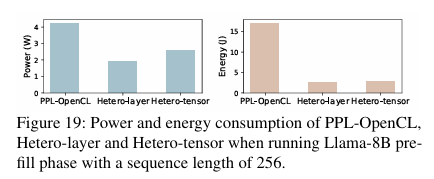
GPU Interference & Energy Consumption
HeteroLLM의 prefill phase를 돌리는 동안 graph rendering 등이 필요한 다른 GPU application에 대한 interference가 얼마나 발생하는지 확인했다. GPU submission queue를 fully-occupy하는 PPL과 달리 HeteroLLM은 GPU capacity를 충분히 남겨두므로 mobile 게임(LOL: Wild Lift를 돌렸다고 한다.)과 함께 잘 돌릴 수 있다고 한다.
고려할 만한 점은, decoding phase에서는 GPU가 많이 사용되는데 이 경우에 대한 실험 결과는 나와있지 않다. decoding phase에는 interference가 존재할 것으로 추정된다.
NPU에 비해 GPU가 power consumption이 높고, HeteroLLM은 NPU를 primary computing unit으로 활용하므로 아래 그래프와 같이 power consumption이 적다. 또한 energy는 power와 execution time의 곱고, HeteroLLM의 execution time 또한 더 짧으므로 energy consumption도 더 적다.
결론
해당 논문에서는 GPU-NPU parallelism을 효율적으로 구현하여 정확도 손실 없이도 빠른 속도를 확보하는 HeteroLLM을 제안했다.
- layer-level/tensor-level heterogeneous execution으로 GPU/NPU를 효율적으로 활용했다.
- Fast synchronization으로 synchronization overhead를 줄였다.
- Partition solver로 최적의 partition 전략을 결정했다.
이때 model에 대한 quantization으로 W4A16만을 사용했지만, int computation을 수행하는 등의 다른 기법을 적용하여 더욱 가속화할 수 있을 것으로 기대된다.
코드가 배포되어 있지 않아서 디테일한 구현 및 실제 성능은 확인이 어렵다. 특히 solver에 대한 부분이 구체적으로 어떻게 잘 구현되고 실행되는지 궁금하다.
Qualcomm 8 Gen 3에서만 실험했으므로 하드웨어 종속적인 결과일 수 있다.
NPU 및 computing graph, 그리고 inference engine에서의 최적화에 대해 처음 접했는데, 다양한 하드웨어적 architecture를 고려해서 성능을 향상시킨다는 점이 흥미로웠다. 그러나 이 논문에 대해서는, partition을 통한 heterogeneous execution이라는 method 자체는 독특하지만 논리 흐름이나 결과가 그렇게까지 잘 다듬어진 것 같지는 않다는 느낌을 받았다.