[Paper Review] OpenVLA: An Open-Source Vision-Language-Action Model
지난 번 읽어본 Efficient VLA survey 논문에 이어, 이번에는 해당 survey에서 소개하는 여러 논문 중 거의 가장 인용수가 높으면서 그 이름대로 코드와 모델이 오픈소스인 OpenVLA(PMLR 2025, 1435회 인용)라는 논문을 읽어봤다.
관련 내용을 잘 설명하고 있는 블로그 글인 옥토와 오픈VLA 심층 분석(25.12.14.)도 읽어보면 좋다.
Introduction
Abstract & Motivation
로봇 공학 분야에서는 오랜 시간 동안 특정 상황과 기기에 최적화된 specialist 모델을 개발해 사용해왔지만, 이런 방식은 공장 등 정형화된 환경을 벗어나 일상생활 등 비정형화된 환경에 적용되었을 때의 한계가 명확하다. 기존 robotics 관련 모델들의 주요 한계는 dataset 자체가 너무 작고 제한되어 있어서 generalization 능력과, robustness가 부족하다는 것이다. 반면 internet-scale dataset으로 pretrain된 vision-language foundation model들은 높은 generalization 능력을 가지고 있고, 이에 따라 pretrained vision-language foundation model들을 core block으로 사용하여 generalist 모델을 개발하려는 시도가 이루어지고 있다.
하지만 앞선 연구에서 제안하는 최신 generalist 모델들은 1) 오픈소스가 아니고, 2) 모델을 새로운 환경/하드웨어에 deploy하는데에 있어 best practice가 아니라는 한계가 있다. 이런 배경에서 저자는 generalization 능력을 갖춘 VLA가 기존의 오픈소스 language model들과 같이, 오픈소스여야 하고 효율적인 fine-tuning을 지원해야 한다고 주장한다.
이에 따라 이 논문에서 제안하는 VLA인 OpenVLA(PMLR 2025, 1435회 인용)는 다음과 같은 특징을 가지고, 기존의 SOTA였던 RT-2-X, pretrained model인 Octo를 outperform했다.
- pretrained vision-language foundation model을 backbone으로 하고, Open X-Embodiment dataset에서 fine-tuning해 generalization 능력을 갖췄다.
- 오픈소스로 배포된 VLA 모델이다.
- LoRA와 quantization을 활용한 효율적인 fine-tuning 및 inference를 지원한다.
VLM and VLA
Vision-Language Model(VLM)의 주요 architecture는 pretrained vision encoder와 pretrained language model을 사용해 모델을 구성하는 형태이다. 이때 vision feature를 tokenize하여 language model의 space로 projection하는 식으로 두 모델을 연결해 사용한다.
robototics에서는 로봇의 조작을 위해 이런 VLM을 적용하려는 시도가 계속 이루어지고 있었는데, 최근 많은 연구는 pretrained VLM을 robot action을 예측하도록 fine-tuning하는 방법을 사용한다. 본 논문에서는 이런 구조를 가지는 VLM을 Vison-Language-Action Model(VLA)이라고 한다. 즉, VLA는 VLM의 추론 능력과 학습 방식을 활용해 로봇 조작을 수행한다.
Baselines
최근 robotics의 트렌드는 multi-task에 대한 처리가 가능한 generalist를 만드는 것이다. OpenVLA 논문에서 언급하는 baseline 모델은 Octo와 RT-2-X가 있다.
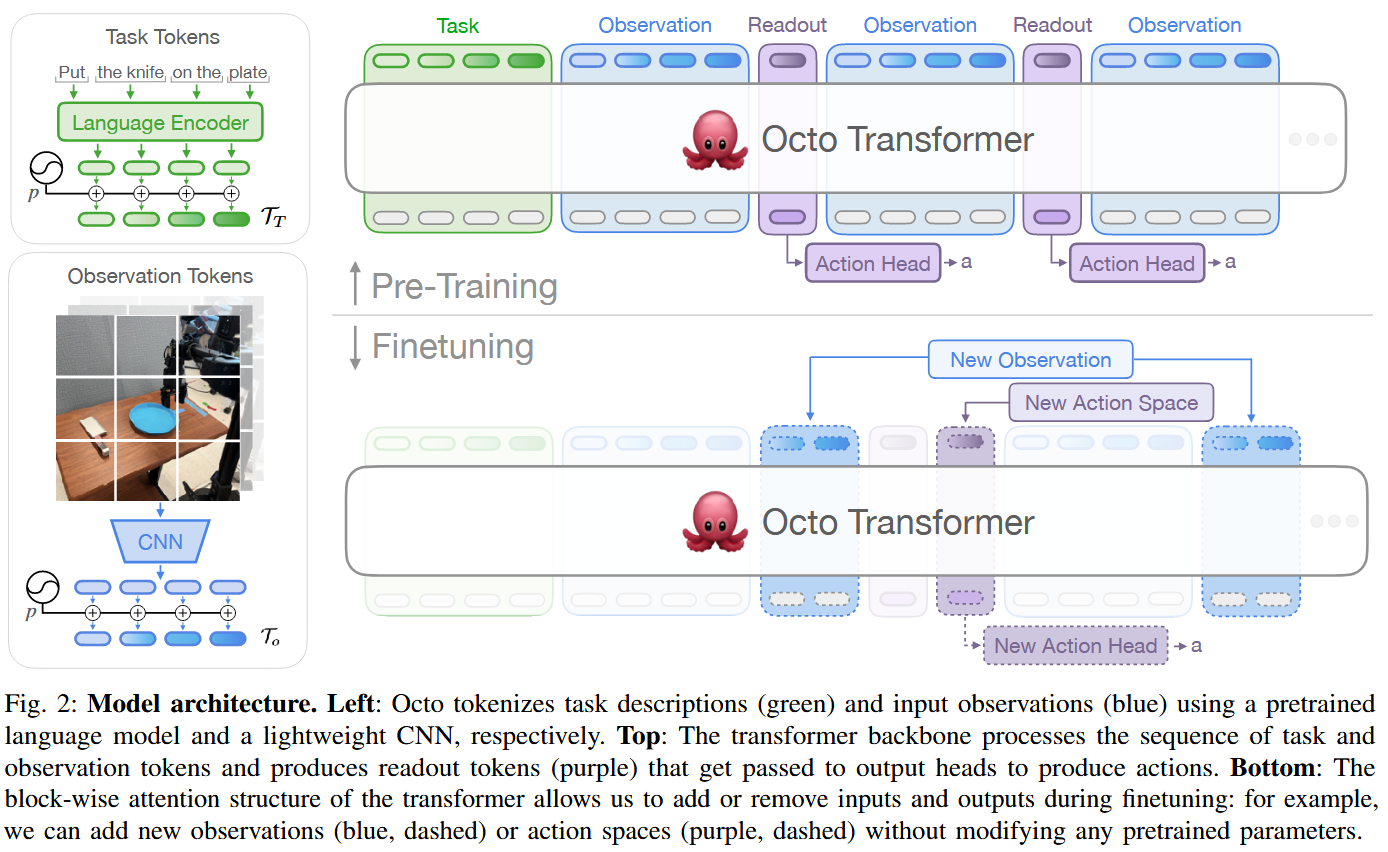
Octo(RSS 2024, 831회 인용)는 93M 크기의 오픈소스 VLA이다. 그 아키텍처는 다음 그림과 같다. pretrained language tokenizer로 T5-base를 사용했고, image tokenizer로 CNN을, backbone 모델로는 ViT와 동일한 크기의 transformer를, action decoder로는 diffusion process를 수행하는 action head를 사용했다. 학습 시에는 language tokenizer는 freeze하고 나머지 부분은 pretrain했고, dataset으로는 OXE dataset 중 일부를 선별해 활용했다. 이때 readout token은 action head의 입력으로 사용되는 learnable token으로, BERT의 CLS token과 같은 역할을 가진다. 또한 새로운 로봇에 대한 fine-tuning 시에는 추가적인 observation과 readout/action head를 추가할 수 있다.
Octo는 다른 기기로의 적용과 fine-tuning을 고려하고 있지만, 추가적인 component를 pretrain하여 사용한다. 반면 OpenVLA는 pretrained VLM을 사용하여 더 단순하게 더 좋은 성능을 달성했다.
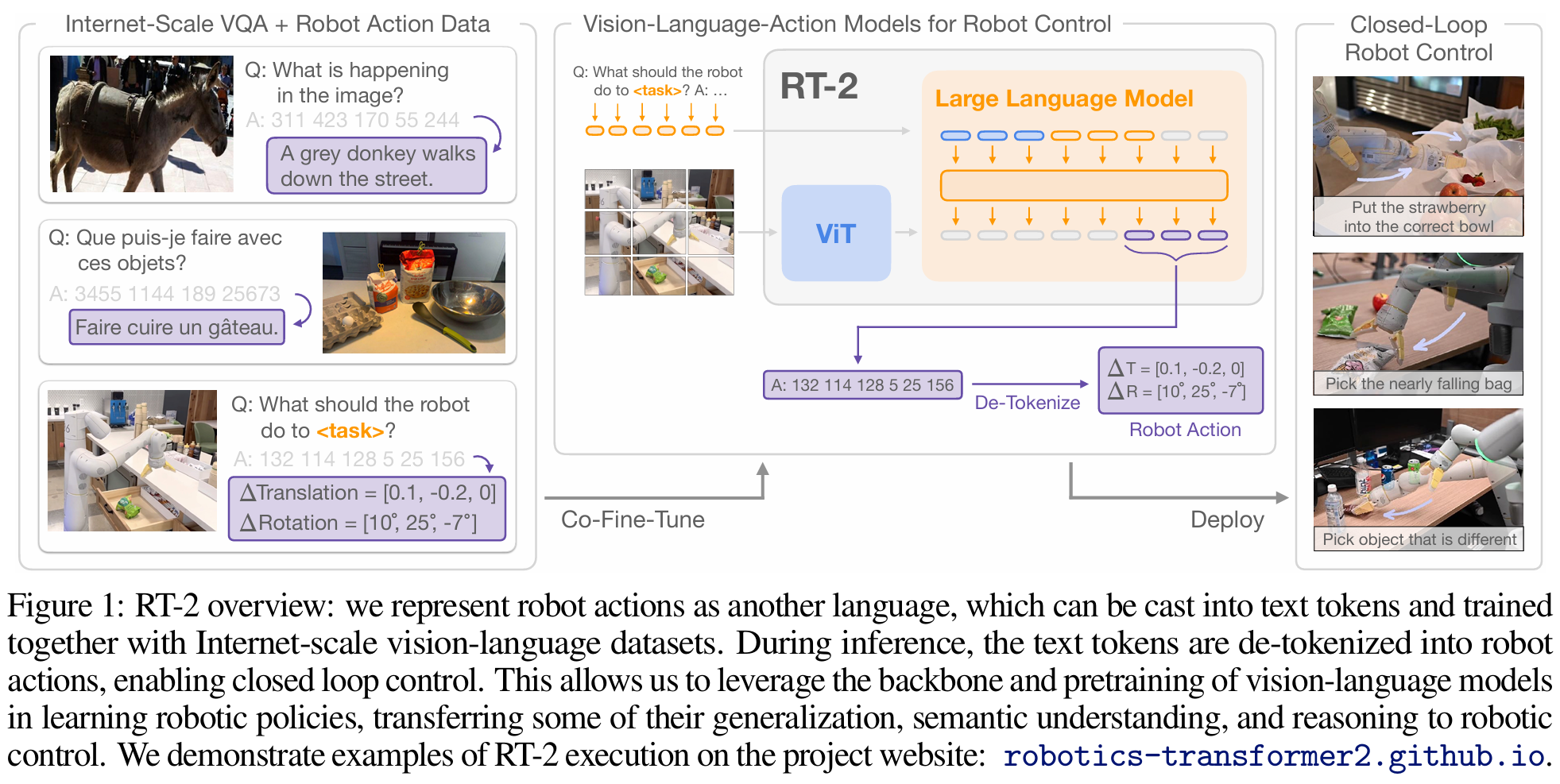
RT-2-X(PMLR 2023, 2390회 인용)는 55B 크기(더 작은 버전도 존재)의 오픈소스가 아닌(closed) VLA로, OpenVLA 이전의 SOTA이다. 그 아키텍처는 다음 그림과 같다. RT-2-X는 internet-scale에서 pretrain된 VLM인 PaLI-X와 PaLM-E을 backbone으로 사용했고, OpenVLA와 유사하게 기존 token들 중 256개를 action token으로 활용했다. 학습 시에는 RT-1-X에서 사용했던 robot data와 internet-scale dataset인 WebLI dataset을 함께 사용했다.
RT-2-X는 하나의 로봇이나 simulation에서의 학습과 평가에만 집중하고, 새로운 로봇에 대한 효율적인 fine-tuning을 지원하지 않는다. 또한 오픈소스가 아니다. 반면 OpenVLA는 성능이 더 좋고, 효율적인 fine-tuning을 지원하면서, 오픈소스이다.
OpenVLA
Architecture
OpenVLA는 다음 그림과 같이 pretrained VLM인 Prismatic-7B VLM을 backbone으로 사용하는 architecture를 가진다.
OpenVLA는 RT-2-X처럼 기존 token들 중 256개를 action token으로 해, action token을 예측하도록 Prismatic-7B VLM을 fine-tuning한다. 즉, discrete output language token과 continuous robot action을 mapping한 것으로 볼 수 있다. 이때 action token에는 robot action을 256개의 bin(구간)으로 나눠 mapping한다. bin width는 training data에서 action 값에 대한 백분위수를 사용해 제1백분위수와 제99백분위수 사이를 uniform하게 나누는 값으로 지정한다(RT-2-X와 달리 outlier를 제외한 것.). 이에 따라 LLM token 중 총 256개를 action token으로 사용해야 하는데, Llama tokenizer는 100개의 speical token만을 가지므로 least used token들을 overwrite해 활용한다(이는 가장 마지막 256개의 token이다.).
이후 N차원의 action 값이 필요한 로봇에 대해 예측을 수행한다고 가정하면, autoregressive하게 action token을 하나씩 생성해 0~255사이의 정수 값으로 구성되는 총 N개의 action token을 생성한 뒤 해당 값들로 로봇을 조작한다. 예를 들어, $\Delta x, \Delta y, \Delta z, \Delta roll, \Delta pitch, \Delta yaw, gripper$로 차원이 7인 action 값이 필요한 로봇의 경우 한 번의 inference에서는 7개의 값 각각에 대응되는 token을 모두 출력하는 과정이다.
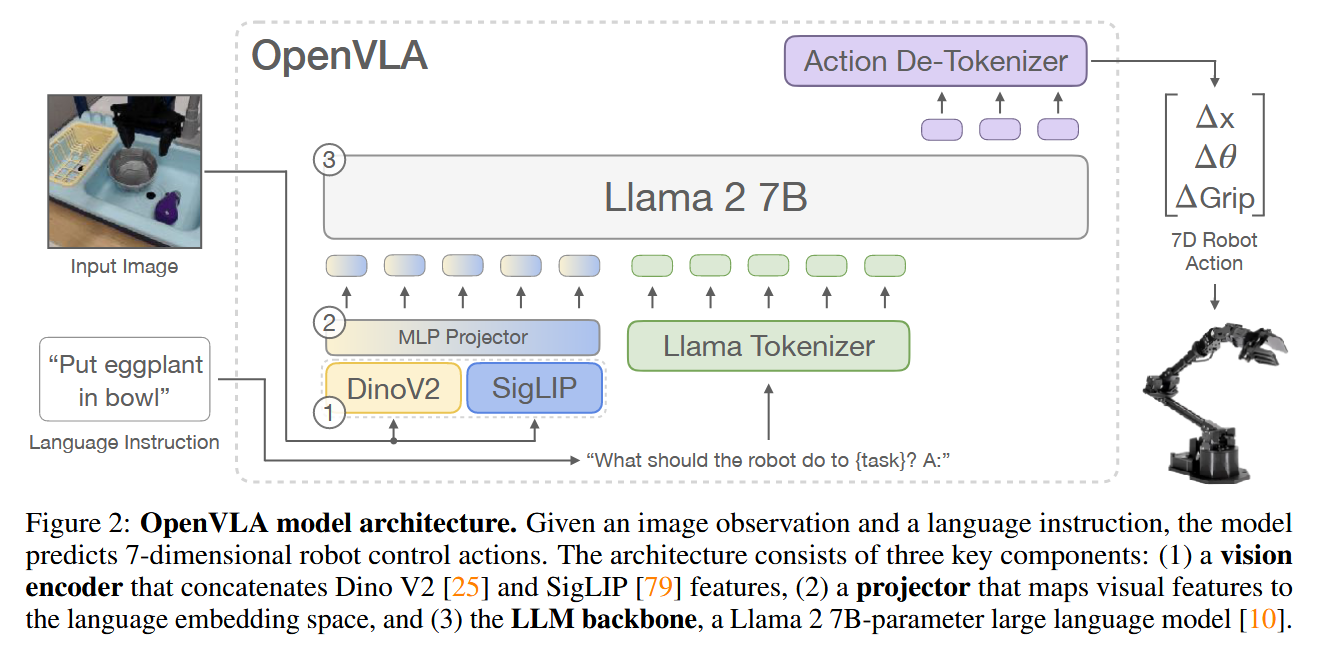
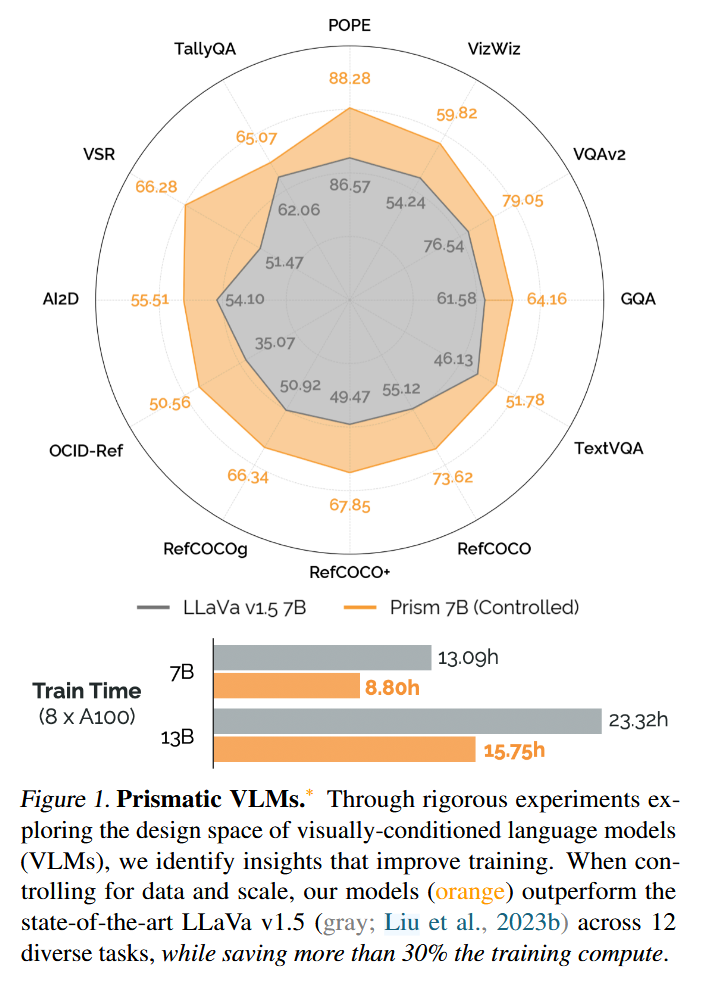
OpenVLA에서 사용하는 Prismatic-7B VLM는 Prismatic VLMs paper(ICML 2024, 236회 인용)의 VLM이다. 해당 논문에서는 VLM이 가지는 여러 가지 design decision들이 존재하지만 최적의 design이 under-explore된 것에 착안하여, VLM을 평가하는 unified framework를 정의하고 여러 model checkpoint를 제공한다. 또한 VLM design에 대한 평가 결과를 바탕으로 다음 그림과 같이 Prismatic-7B VLM을 제안한다. Prismatic-7B VLM는 OpenVLA architecture 그림에 나와있는 것처럼, vision encoder로 SigLIP와 DinoV2를, language model로 Llama2와 같이 internet-scale에서 pretrain된 모델을 사용하며, MLP projector로 vision feature를 language embedding space로 projection하는 architecture를 가진다.
이때 visual encoder로 SigLIP와 DinoV2를 함께 사용할 때는 입력 이미지의 각 patch를 두 encoder에 각각 넣어 출력된 두 embedding을 단순히 concat해 사용한다. 이런 encoder 구조가 하나의 encoder만 사용하는 것보다 spatial reasoning에 더 유리하다고 한다. 또한 projector는 단순히 vision embedding을 입력으로 받아 language embedding 크기로 변환하는 MLP이다.
Training
OpenVLA는 action token을 출력하도록 Prismatic-7B VLM를 full fine-tuning한 것이다.
training dataset으로는 Open X-Embodiment(OXE) dataset을 변형해 활용했다. 변형된 dataset은 1) input&output space가 일관적이어야 하고 2) 다양한 embodiment, task, scene들이 training mixture에 포함되어 있어야 한다. 이에 따라 적어도 하나의 3rd person camera가 있으면서, single arm end-effector control만 포함하고, diversity가 낮은 dataset은 제외하는 등 Octo에서 사용한 방식을 사용해 data mixture를 구성했다.
A100 GPU 64개로 14일간 학습을 돌렸고, 학습된 모델은 추론에 VRAM 15GB가 필요하다고 한다. 물론 추후 소개할 quantization을 적용하면 더 적은 VRAM으로 돌릴 수 있다.

Design Decisions
최종 training을 수행하기 전에, 비교적 작은 dataset인 BridgeData V2 dataset에서 다음과 같이 여러 design decision을 수행했다.
VLM backbone으로는 LLaVA, IDEFICS-1도 사용해봤는데, IDEFICS-1 < LLaVA < Prismatic VLM 이었다. 특히 multi-object일 때 그랬는데, 아마 spatial reasoning 능력 때문일 것이라고 한다. 또한 모델 코드를 활용하기도 더 쉬웠다고 한다.
여러 VLM bench에서 image resolution을 높이면 성능이 개선되지만, OpenVLA에 대해 실험했을 때는 성능 차이가 없어서 더 적은 resolution을 사용했다. resolution이 높아질수록 vision token 증가에 따른 context length 증가로 computation이 늘어나므로 적은 걸 선택했다.
VLM 관련 기존 연구에선 vision encoder를 freeze하는 게 기존 지식이 보존되어 더 높은 성능을 보였지만, OpenVLA 학습 시에는 함께 fine-tuning하는 것이 성능이 더 좋았다. vision encoder 자체가 robotic control 자체에 대한 지식을 가지고 있지 않았어서 그런 것으로 보인다고 한다.
LLM/VLM 학습 시의 전형적인 fine-tuning epoch은 1~2 정도이지만, OpenVLA 학습 시에는 epoch을 늘려도 성능이 계속 올라가서 27까지 했다고 한다.
leaning rate는 Prismatic VLMs paper에서의 학습에서와 동일한 2e-5가 실험적으로 최적이었다고 한다.
Experiments
본 논문에서 진행한 실험의 목표는 다음과 같은 사항들을 확인하는 것이다.
- 기존 방식과 비교해서 OpenVLA가 multi-robot과 다양한 task에 대해서 성능이 좋은가?
- fine-tuning해 새로운 robot task로서 사용되기에 좋은가?
- PEFT나 quantization을 적용해 더 accessible하게 할 수 있는가?
Out-of-the-Box
OpenVLA의 out-of-the-box 성능은 OpenVLA, RT-1-X, RT-2-X, Octo간의 비교를 수행했다. 사용한 로봇은 WidowX(BridgeData V2 dataset의 로봇)와 Google robot(RT-1-X, RT-2-X에서 평가에 사용한 로봇)이다. 평가에는 몇 가지 generatliztion task를 정의해 각 세부 task별로 여러 번의 trial을 실제로 로봇을 사용해 시도하며 성공 횟수를 측정했다.
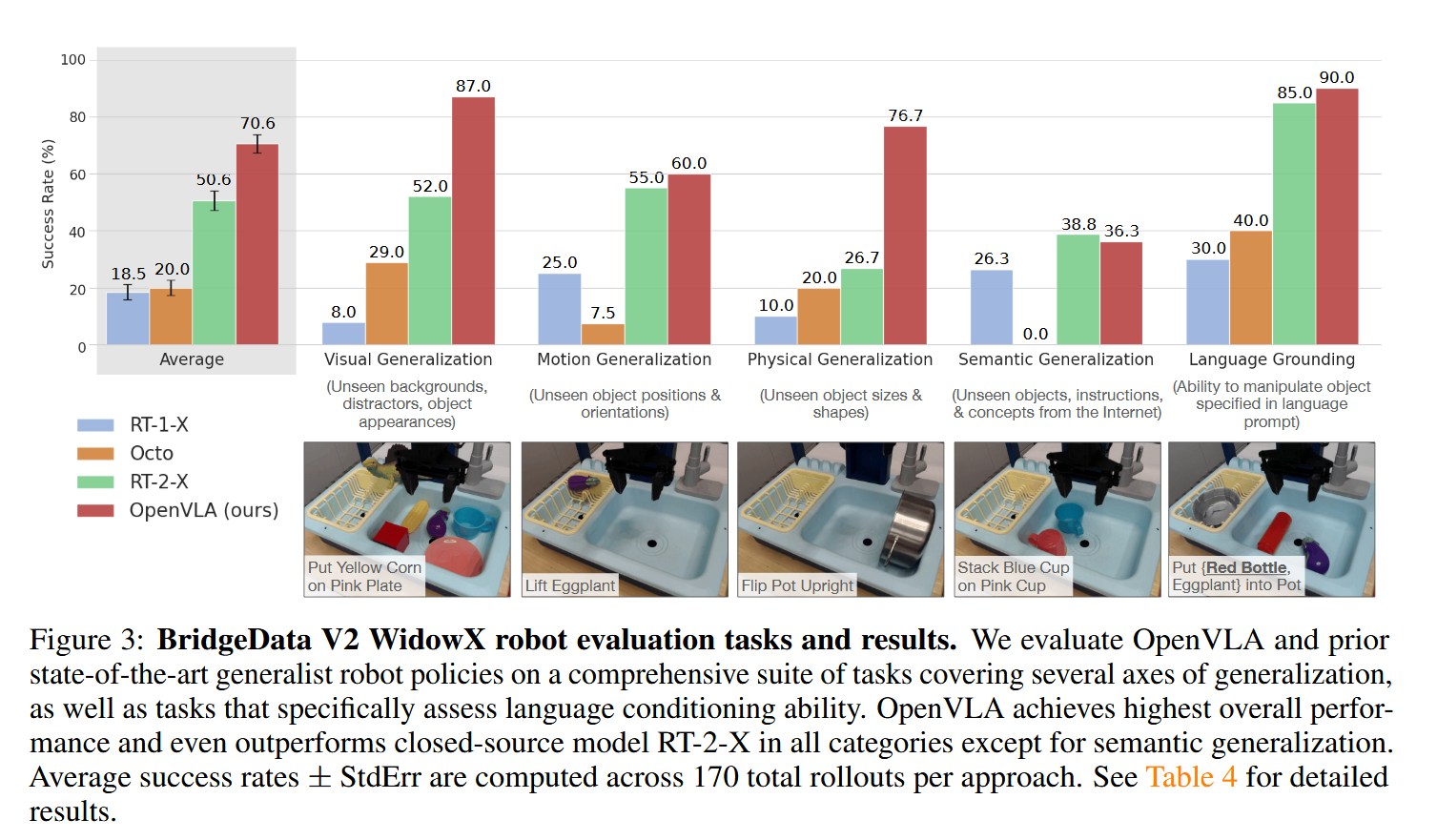
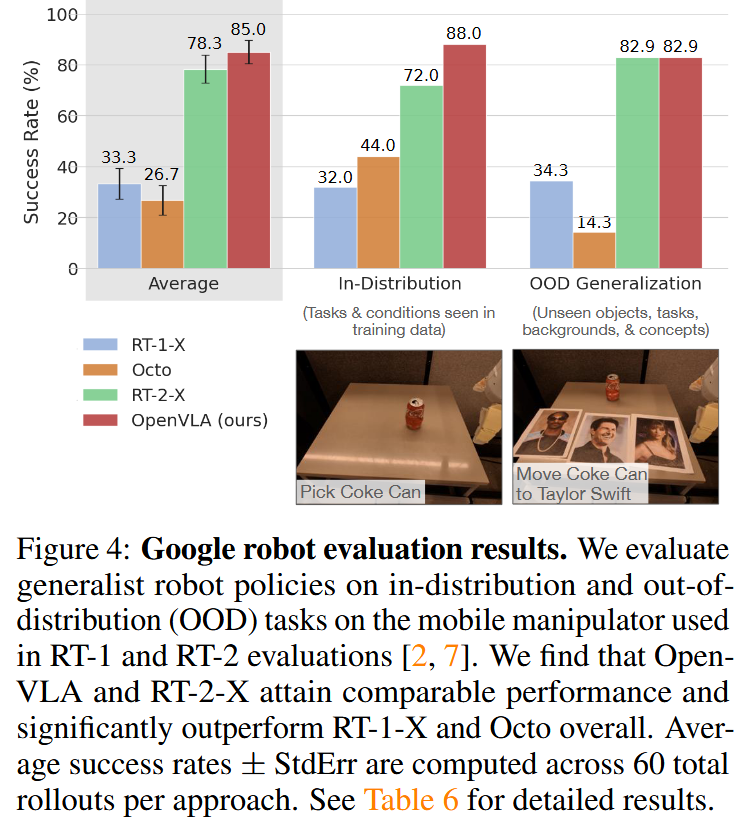
대부분의 task에서, 그리고 평균값에서 OpenVLA가 가장 높은 성공률을 보였다. internet-scale 데이터로 학습되지 않은 RT-1-X, Octo는 generalization 능력이 부족해 distractor 객체가 존재할 때 구분하는 걸 잘 못했다. 반면 internet-scale로 pretrain된 VLM을 사용해 만든 RT-2-X와 OpenVLA는 distractor가 존재해도 잘 동작했다. 또한 OpenVLA(7B)는 RT-1-X(55B)보다 훨씬 작음에도 dataset에 따라 비슷하거나 더 좋은 성능을 보였다. 더 크고 좋은 규모의 dataset(OXE 기반 dataset)을 사용해 훈련했고, fused vision encoder(SigLIP와 DinoV2)를 사용했기 때문이라고 한다. 하지만 semantic generalization에 대해서는 RT-2-X가 더 좋았는데, 이는 RT-2-X가 학습 시에 robot data와 internet data를 섞어서 사용해서 pretraining knowledge를 보존했기 때문이라고 한다.
Adaptation to New Robot Setups
fine-tuning을 통해 새로운 robot setup에 적용하는 실험은 OpenVLA(full fine-tuning을 한 버전), OpenVLA(scratch)(fine-tuning을 하지 않은 버전), diffusion policy, diffusion policy(matched), Octo(fine-tuning을 한 버전) 간의 비교를 수행했다. RT-2-X는 오픈소스가 아니고 API에서 fine-tuning을 지원하지 않는다고 한다. 사용한 로봇은 Franka Emika Panda 7-DoF robot arm이고, Franka-Tabletop과 Franka-DROID에서 평가했다.
Diffusion Policy(IJRR 2024, 1566회 인용)는 robot action을 transformer 기반의 diffusion model로 수행하는 모델로, 이미지와 로봇의 현재 물리적 상태를 입력으로 받아, action의 chunk를 예측한다. 이 실험에서 비교에 사용하는 diffusion policy(matched)는 이미지만 입력으로 사용하고, chunk 대신 하나의 출력을 사용하도록 해 입출력을 OpenVLA와 맞춘 것이다. diffusion policy와 diffusion policy(matched)는 scratch부터 pretrain되었다고 한다.
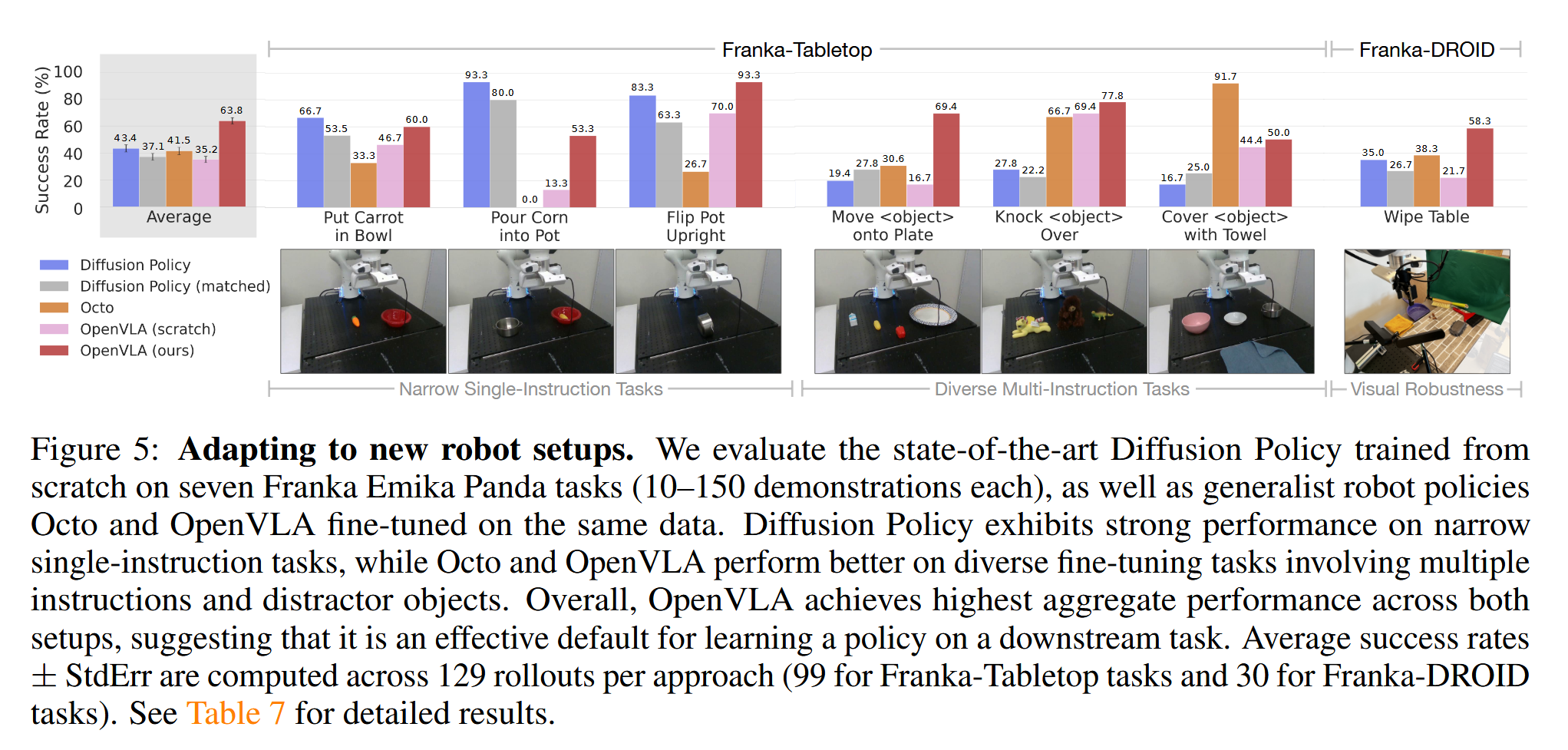
평균적으로 OpenVLA가 제일 좋았다. 하지만 narrower single-instruction task, dexterous task(정확하고 부드러운 조작 필요)에서는 diffusion policy가 좋았는데, 이는 diffusion policy의 아키텍처적 특성에 의한 것이라고 한다. 반면 multiple object가 있거나 language conditioning이 필요한 경우 generalist policy가 더 좋았고, 이는 OXE dataset으로 학습시켰어서 그렇다고 한다. OpenVLA에서도 diffusion policy의 방식을 일부 활용하면 더 세밀하고 정확한 조작이 가능할 것이라고 언급한다.
PEFT
OpenVLA에 대한 full fine-tuning은 8개의 A100 GPUs를 사용했을 때 task에 따라 5~15시간이 걸린다고 한다. 이에 따라 Parameter Efficient Fine-Tuning(PEFT)가 가능한지를 확인하기 위해 full fine-tuning, last layer only(transformer block의 last layer와 token embedding matrix만 학습), frozen vision(vision encoder만 freeze), sandwich fine-tuning(last layer only에 vision encoder까지 학습), LoRA(모든 linear layer에 사용)를 비교했다.
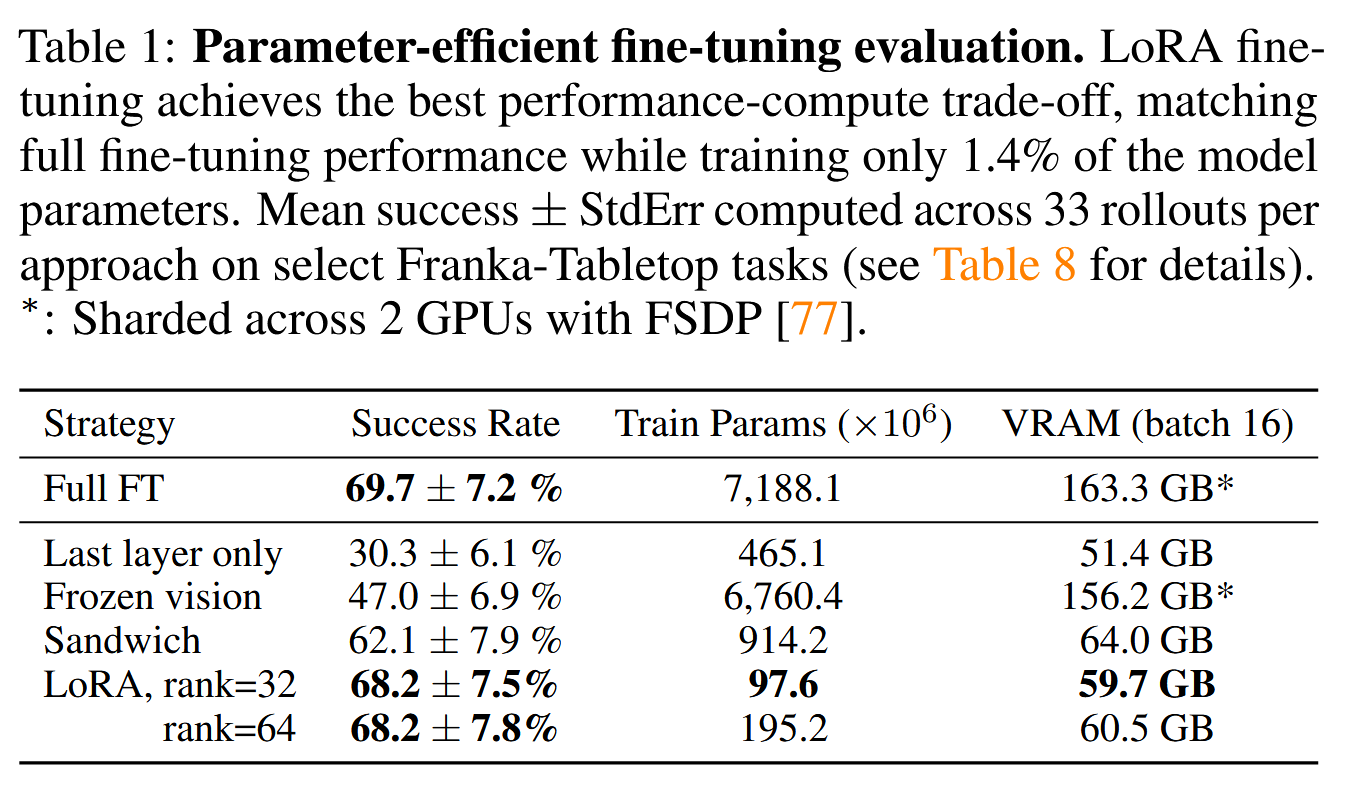
vision encoder를 학습시키지 않는 방식은 성능이 크게 떨어졌고, LoRA의 성능이 가장 좋았다. 이때 rank는 상관이 거의 없었다. 또한 LoRA를 사용하는 경우 하나의 A100 GPU로 10~15시간이면 학습이 완료됐다고 한다.
Quantization
Octo(93M)와 비교하면 OpenVLA(7B)가 inferece에 VRAM이 많이 필요하다 보니, quantization을 적용하는 실험도 수행했다.
modern LLM quantization 기법인 QLoRA(NeurIPS 2023, 4802회 인용)와 LLM.int8()(NeurIPS 2022, 1734회 인용)을 사용해 INT4, INT8로 precision을 낮춰서 비교했고, GPU별 speed, BridgeData V2 dataset 중 8가지 task에서 precision별 성공 횟수를 확인했다.
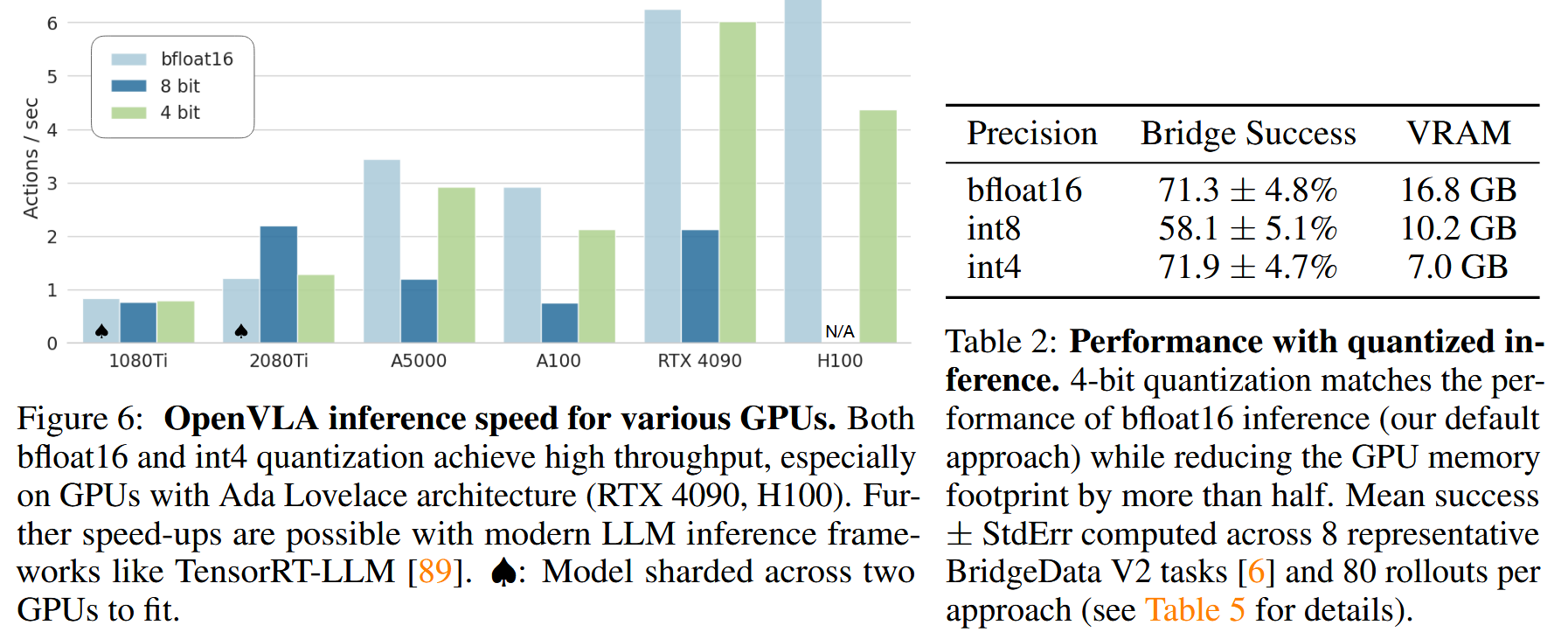
INT8의 경우 quantization에 의한 추가 연산에 따른 overhead가 커서 speed(frequency)가 떨어졌는데, BridgeData V2 dataset이 수집된 frequency(5Hz)에 비해 frequency가 떨어지다 보니(1.2Hz) system dynamics와 맞지 않아 성능도 크게 떨어졌다고 한다. 반면 INT4는 GPU memory transfer 시간 감소에 따른 gain이 quantization overhead보다 커서 speed(frequency)가 크게 떨어지지 않았고(3Hz), 성능도 보존됐다.
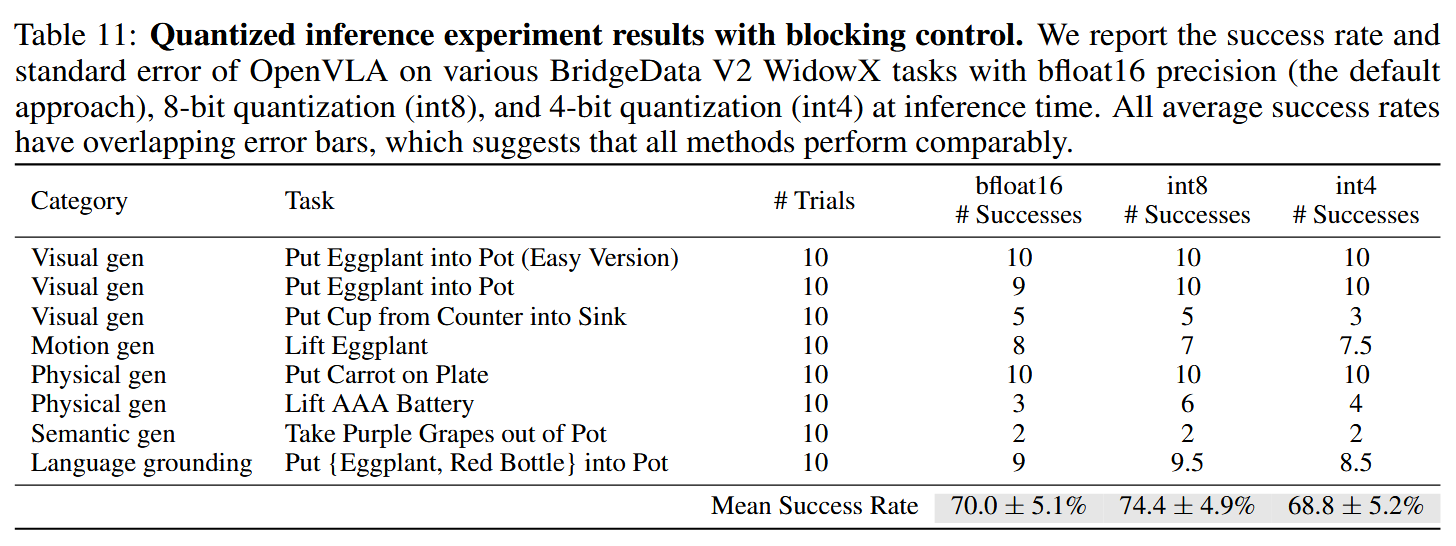
대신 blocking control을 적용해, 예측한 action이 모두 실행된 이후 그 다음 action을 예측하도록 해서 frequency를 배제하고 action의 정확도만 확인해 보면 다음 표와 같이 INT8의 성능이 높게 나오는 것을 확인할 수 있었다고 한다.
dataset이 수집된 frequency와 inference에서의 control frequency에 차이가 나면 success rate가 떨어지는데, 이는 모델이 해당 dataset에서 기대하는 시간 간격 내에서의 물리적 변화를 예측하게 되기 때문이라고 한다. 구체적으로 OpenVLA가 예측하는 값이 robot contorller에서 non-blocking으로 어떻게 처리되는지는 더 알아봐야 한다.
결론
Pros and Cons
OpenVLA는 앞서 설명한 것처럼 다음과 같은 사항을 달성한다.
- pretrained vision-language foundation model을 backbone으로 하고, Open X-Embodiment dataset에서 fine-tuning해 generalization 능력을 갖췄다.
- 오픈소스로 배포된 VLA 모델이다.
- LoRA와 quantization을 활용한 효율적인 fine-tuning 및 inference를 지원한다.
하지만 모델 크기가 7B이고, 속도도 충분히 빠르지 않고, 사용한 GPU를 고려하면 아직 edge에서 돌릴 순 없을 거 같다. OpenVLA github.io에서 확인할 수 있는 시연 영상에 배속이 얼마나 들어갔는지를 생각해 보면, 여전히 inference frequency(speed)가 너무 낮다. 또한 OpenVLA는 Octo보다 훨씬 크고 action quantization error가 존재하므로 정밀한 움직임으로 제어하긴 어렵다. 이에 따라 OFT, FAST 등의 후속 연구가 나왔다고 하니 읽어볼만 할 듯하다.
향후 방향
해당 논문은 읽어보며 VLA 관련 연구가 어떤 식으로 이뤄지고 있는지를 알 수 있었다. 하지만 해당 모델은 edge에서 바로 돌리기엔 너무 크고, 속도도 충분히 빠르지 않다. 이렇게 LLM을 backbone으로 사용해 generalization 능력을 확보했다면 모델 자체가 많이 작아지긴 어려울 거 같으니, 이에 따라 edge-server의 협응으로 VLA를 serving하는 system이 정확도 및 속도 측면에서 효과적일 것으로 보인다. 현재 내 관심사는 edge에서의, 또는 edge-server간 협응을 통한 efficient AI model serving이고, 이런 쪽으로 더 알아보면 좋을 것 같다.
그래서 다음으로는 다음과 같은 2가지 조사를 추가적으로 수행할 계획이다.
- OpenVLA를 넘어선 가장 최근의 SOTA 모델에서는 어떤 아키텍처를 사용하고 있으며, 어느 정도의 성능을 보이는지 확인한다.
- edge-server간 협응을 통한 VLA serving에는 어떤 선행 연구가 있었는지 확인한다.