[Paper Review] A Survey on Efficient Vision-Language-Action Models
지난 주에는 연구실에서 겨울방학 동안 공부하고 실험해 볼 분야를 찾아봤었다. 현재 내 관심사는 edge에서의, 또는 edge-server간 협응을 통한 efficient AI model serving이다 보니, edge에서의 효율적이고 빠른 연산이 중요한 Efficient VLA 관련 논문을 읽어보려 했다. 이에 따라 본 포스트에서는 교수님께서 제안서와 함께 공유해주신 논문들 중 하나인 A Survey on Efficient Vision-Language-Action Models의 내용을 간략히 정리한다. 해당 survey 논문은 2025년 10월 27일에 arxiv에 올라온 논문으로, 나름 최신 논문이면서 efficient VLA와 관련된 논문들을 model/training/dataset의 관점에서 여러 세부 분야로 잘 분류하여 정리해 놨다.
VLA
VLA란?
Vision-Language-Action Model(VLA)은 vision-language 입력을 받아 로봇이 수행해야 할 physical action을 예측하는 multimodal model이다. VLA는 자율주행, family robot, smart home, industrial manifacturing, medical robot 등 다양한 application에 활용될 가능성이 있다.
VLA는 기본적으로 LLM/VLM을 활용하므로 높은 inference latency와 저조한 frequency를 보이게 되고, 학습과 데이터셋 구성에 많은 비용이 든다. 심지어 edge device(로봇)에서 모델을 돌리는 경우 제약이 더 심해진다. 이에 따라 VLA를 사용해 edge에서 robot manipulation을 실제로 잘 수행하기 위해서는, 높은 성능을 유지하면서 model/training/dataset 각각에 대해 합리적인 수준의 efficiency를 확보해야 한다.
해당 survey에서는 efficient VLA와 관련된 기존의 연구들을 세 가지 분류인 1) Efficient Model Design, 2) Efficient Training, 3) Efficient Data Collection으로 나누어 소개한다.
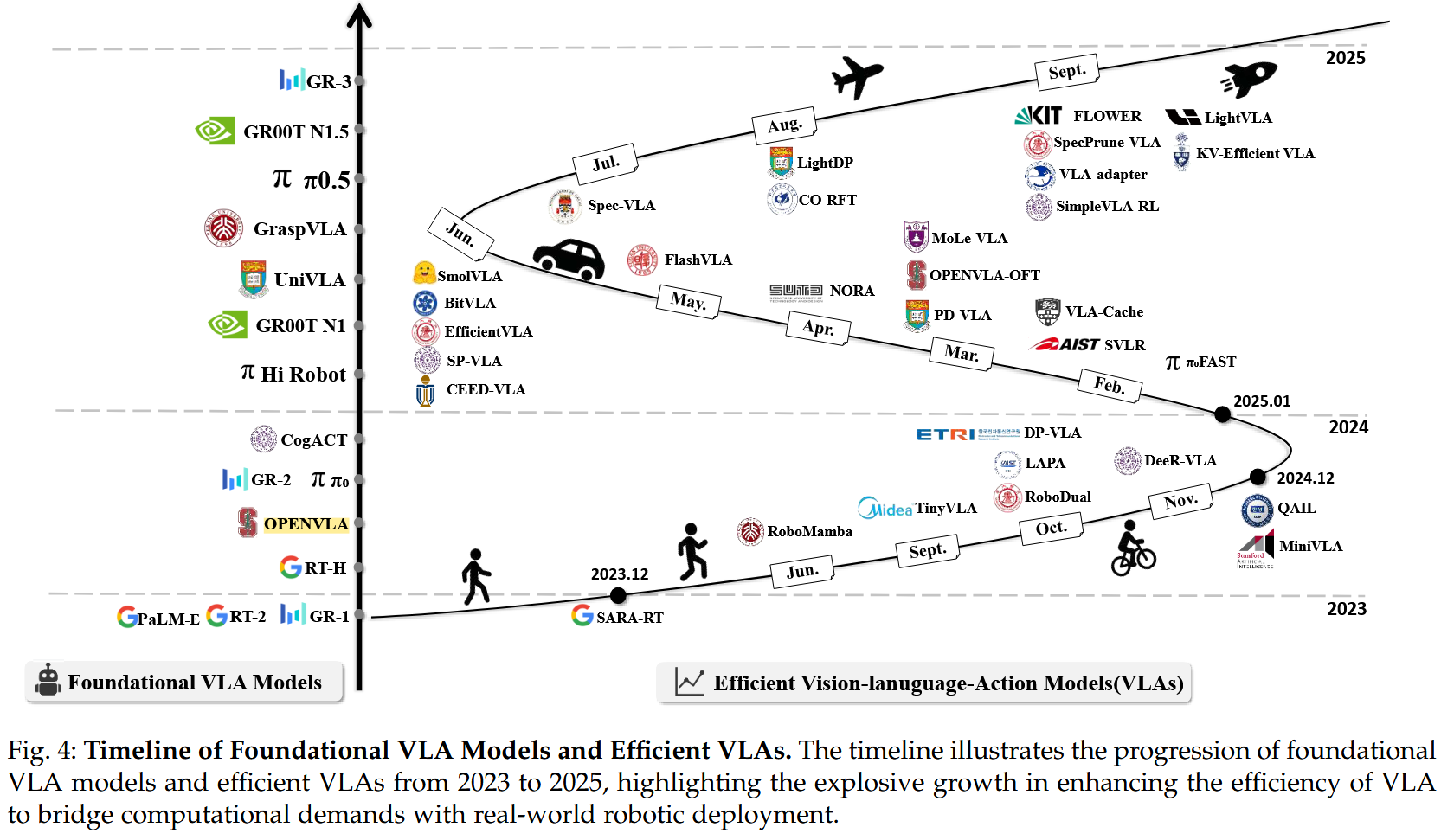
VLA Architecture
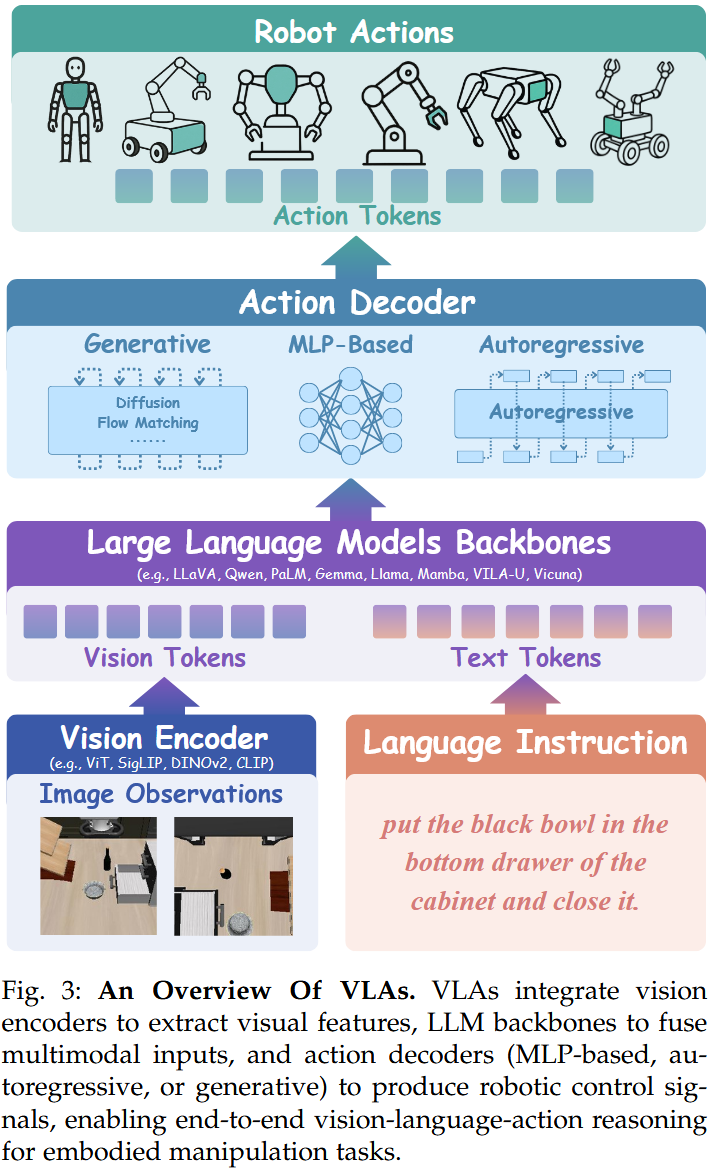
최근의 VLA는 기본적으로 vision encoder, LLM(backbone), action decoder로 구성된 architecture를 가진다. vision encoder로는 ViT, SigLIP, DINOv2, CLIP 등이, LLM backbone으로는 LLaVA, Qwen, PaLM, Gemma, Llama, Mamba, VILAU, Vicuna 등이 사용된다. action decoder는 LLM의 출력을 로봇에서 활용할 수 있는 값으로 변환하는 component로, diffusion/flow matching, autoregressive decoding, MLP-based method 등 여러 방식이 존재한다.
Datasets and Benchmarks
VLA에서 활용하는 데이터셋은 real-world dataset과 simulation data으로 구분할 수 있다. real-world dataset으로는 Open X-Embodiment(OXE), BridgeData, BrideData V2, DROID 등이 있고, simulation dataset으로는 RLBench, RoboCasa, RoboGen 등이 있다. 또한 VLA에서 활용하는 벤치마크로는 Meta-World, LIBERO, SIMPLER, VLABench 등이 있다.
real-world dataset 각각에 대한 구체적인 설명은 다음과 같다.
Open X-Embodiment(OXE)는 구글 딥마인드와 전 세계 여러 기관이 협력하여 구축한 대규모 로봇 데이터셋으로, BridgeData 등 60개 이상의 기존 데이터셋을 결합해 RLDS(Reinforcement Learning Datasets)라는 포맷으로 구성했고, 총 1,400,000개 가량의 episode(trajectory)들을 포함한다. OXE 데이터셋 overview에서 어떤 데이터들로 구성되어 있는지 쉽게 확인할 수 있다. OXE는 다양한 task, 로봇(WidowX, Franka 등 22종), 환경을 아우르고 있어 generalization 및 transfer learning capacity를 학습시키는 데에 사용될 수 있다. 특히 Octo, OpenVLA 등이 OXE로 훈련되었다.
이는 OXE v1에 대한 설명이고, OXE v1.1에서는 DROID 등 12개의 데이터셋이 추가되어 총 2,400,000M개 가량의 episode(trajectory)들을 포함한다.
BridgeData는 UC Berkeley 연구팀이 주도하여 공개한 데이터셋으로, WidowX 250(6축 로봇 팔)을 사용하여 범용적인 가사 노동(Kitchen tasks)에 대한 정보를 담고 있다. 총 7,200개 정도의 episode(trajectory)를 포함한다. 또한 특정 작업에만 특화된 데이터가 아니라, 여러 작업 간의 연결(bridge)을 포함하는 데이터를 가지고 있어 generalization 성능을 높일 수 있도록 했다.
BrideData V2는 BridgeData를 확장한 것으로, 그 규모와 다양성도 증가했고, 모든 데이터에 language label이 포함되어 있어 VLA 학습에 잘 활용될 수 있다. 총 60,000개 가량의 궤적 데이터를 포함한다.
DROID는 Franka Panda(7축 로봇 팔)과 스테레오 카메라를 사용하여 여러 scene과 task를 포함하는 대규모 로봇 데이터셋이다. 총 76,000개 정도의 episode(trajectory)를 포함한다. scene의 다양성이 높고, 스테레오 카메라를 사용하여 depth와 3D 시각 정보를 포함하므로 정밀한 조작을 학습하는 데에 유리하다.
Efficient VLA Related Works
각 세부 연구 분야에 대한 구체적인 설명과 관련 논문은 적어두지 않았는데, 해당 survey 논문에 잘 정리되어 있으니 필요하면 참고하자.
Efficient Model Design
Efficient Model Design은 효율적인 모델 architecture를 다루는 Efficient Architecture와, 기존의 모델을 더 가볍게 만드는 Model Compression으로 나눌 수 있다.
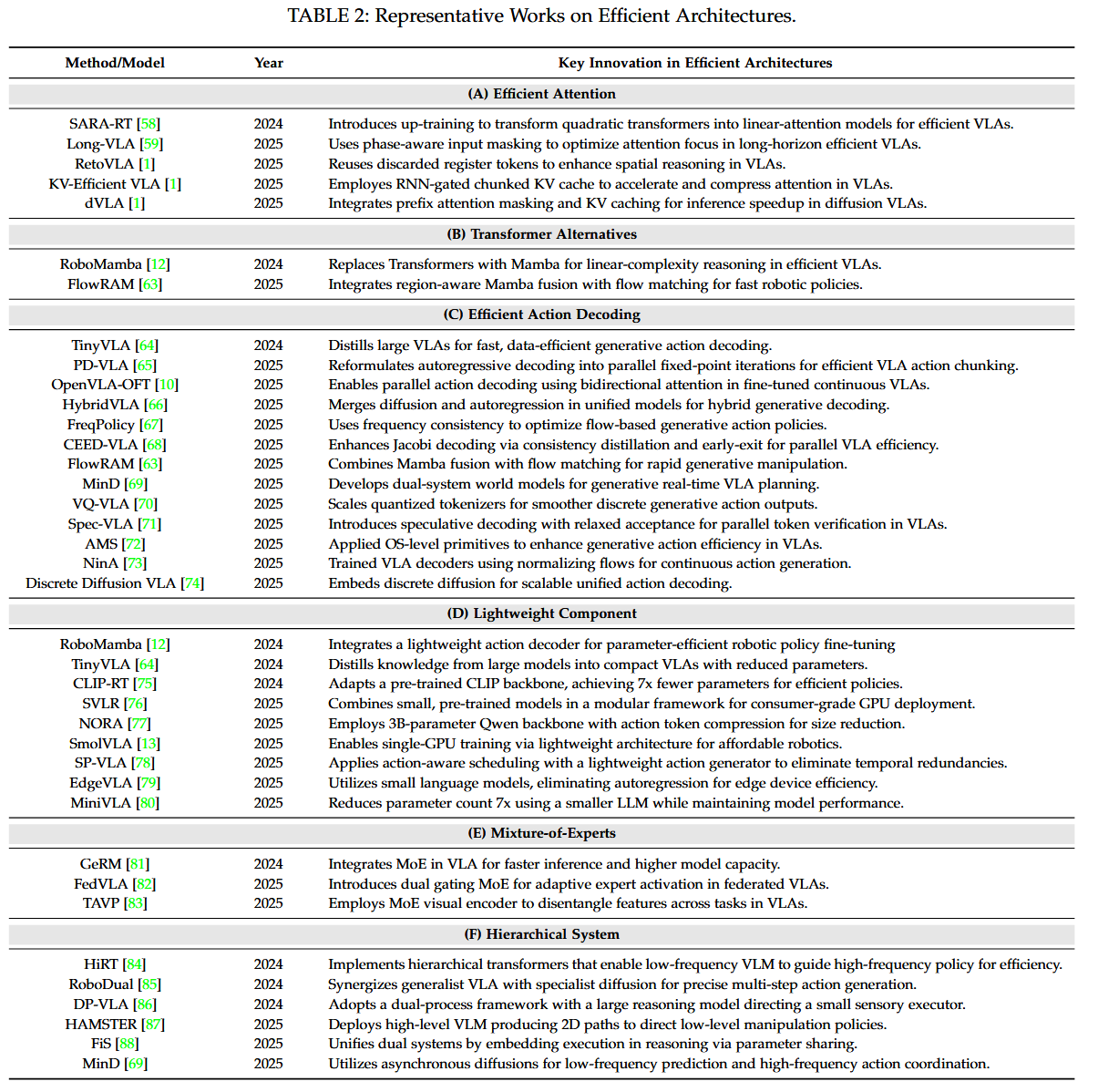
efficient architecture 관련 세부 분야로는 다음과 같은 것들이 있다.
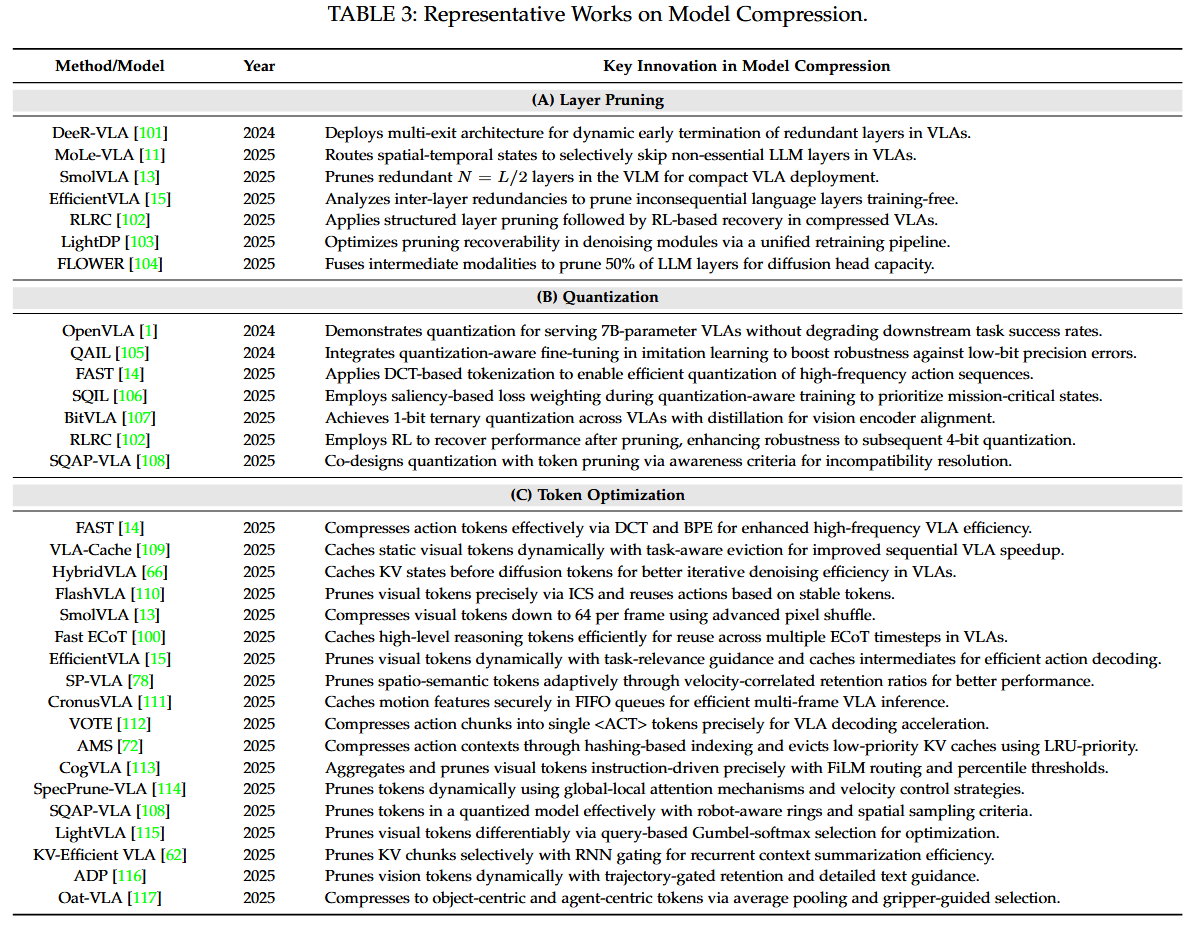
model compression 관련 세부 분야로는 다음과 같은 것들이 있다.
Efficient Training
Efficient Training은 Efficient Pre-Training과, Efficient Post-Training이 있다. VLA는 pretrained LLM/VLM을 backbone으로 사용하므로 robust하고 좋은 성능을 보일 수 있지만, 이에 따라 학습 시에 computationally intensive하고, time-consuming이며, dataset의 품질에 영향을 많이 받는다. 또한 pretrained VLA를 여러 로봇 및 기기에서 downstream task를 잘 수행할 수 있도록 하려면 pretraining만이 아니라 post-training도 중요하다.
efficient pre-training 관련 세부 분야로는 다음과 같은 것들이 있다.
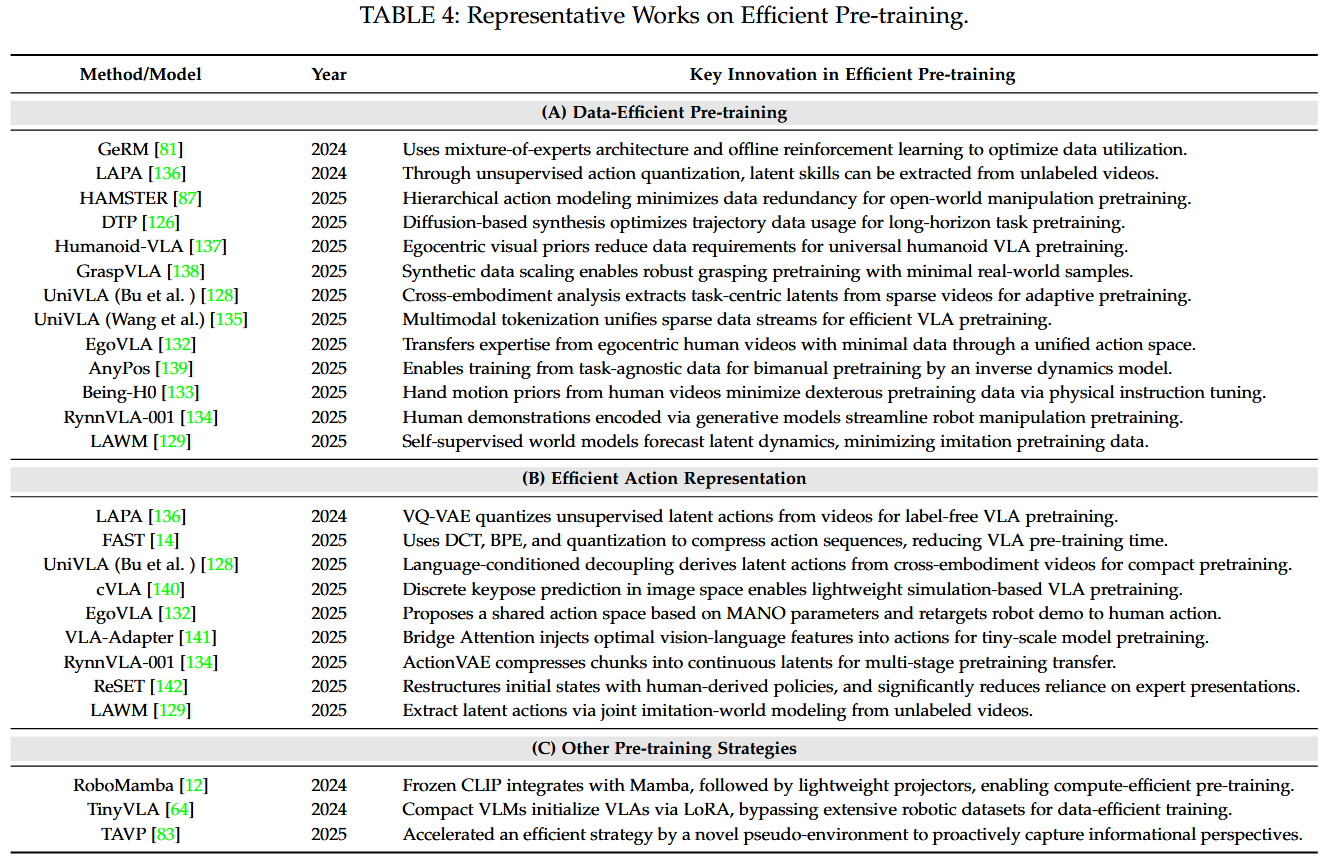
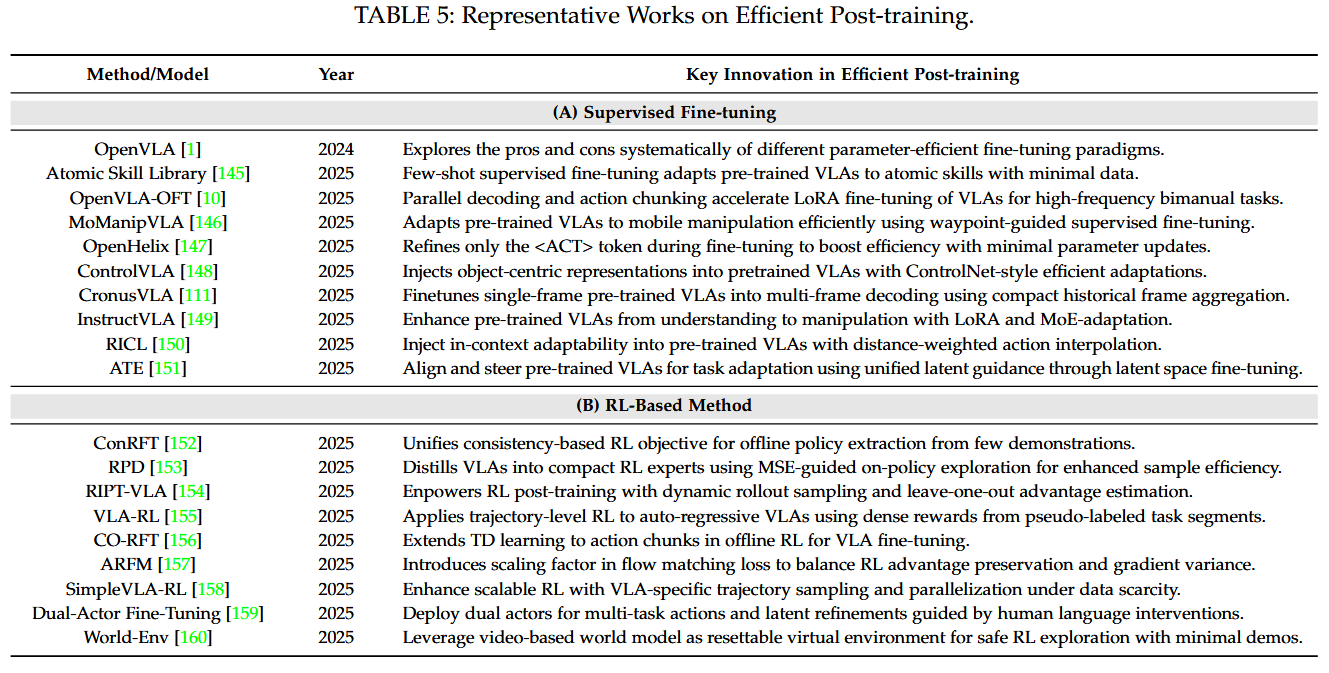
efficient post-training 관련 세부 분야로는 다음과 같은 것들이 있다.
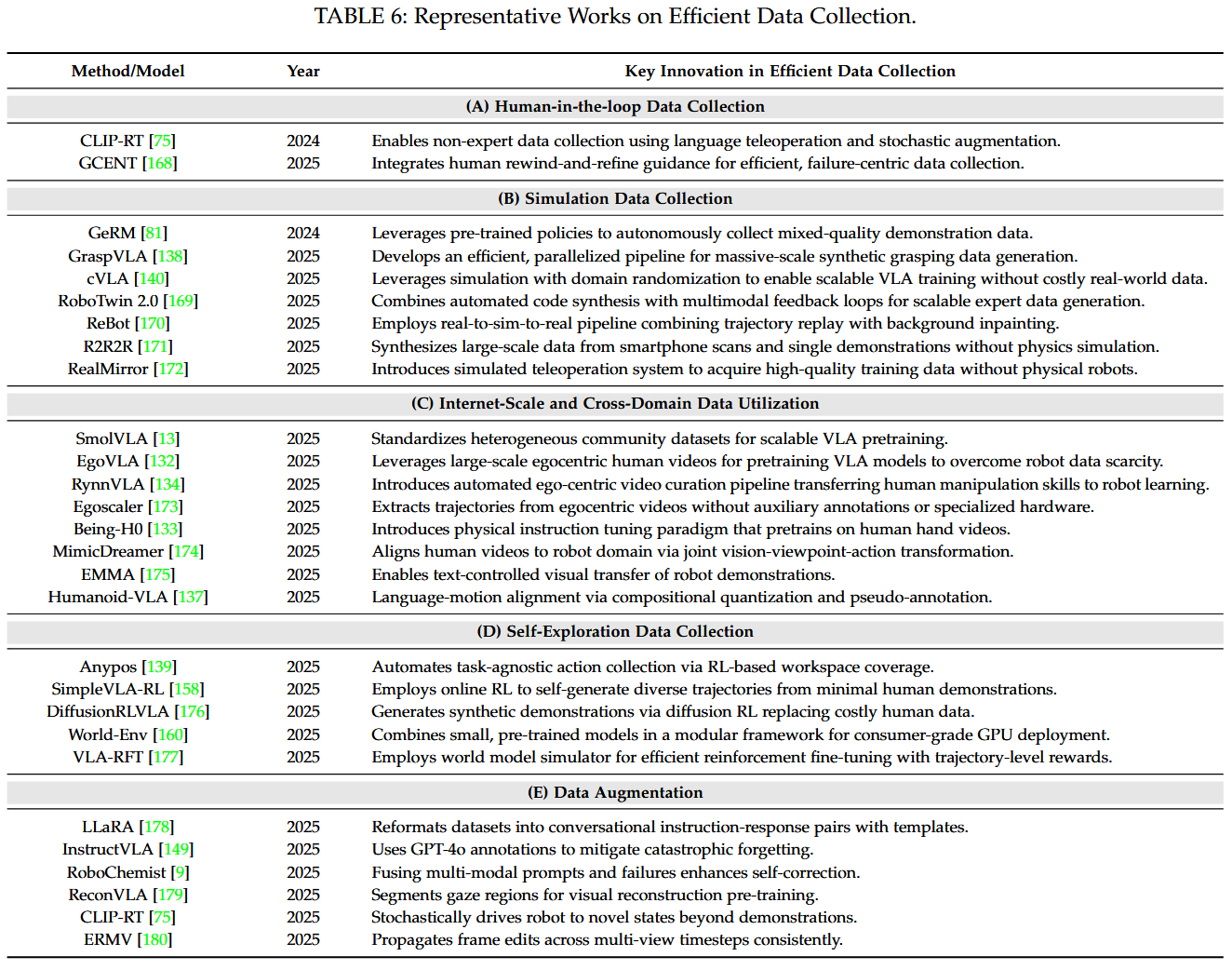
Efficient Data Collection
Efficient Data Collection 관련 세부 분야로는 다음과 같은 것들이 있다. 기존의 LLM이 internet-scale data를 활용할 수 있는 것에 비해, VLA는 그런 형태의 데이터를 직접 활용할 수 없다. 이에 따라 사람이 직접 참여하여 좋은 품질의 데이터셋을 만들기도 하지만 이는 비용과 시간이 너무 많이 든다. 다음 표에서 소개하는 data collection 관련 연구들에서는 simulation data를 활용하는 방식, internet-scale data 또는 다른 domain의 데이터를 활용하는 방식, 기기가 직접 학습 데이터를 수집하도록 하는 방식, augmentation 기법 등을 다룬다.
Future Works
이 survey에서는 model/training/dataset 별 future work도 제안한다.
- model과 관련해서는 context-aware dynamic token pruning, modality-agnostic backbone, hardware-software co-desgin에 의한 optimization을 언급했다.
- training과 관련해서는 federated paradigm, physics-informed objective, meta-learning, self-improving training을 언급했다.
- dataset과 관련해서는 diffusion guided synthesis, further reduction to sim-to-real gap, multi-agent exploration을 언급했다.
결론
어떤 실험이나 시도를 하기 전에 우선 진입하려는 분야와 선행 연구에 대한 충분한 지식과 이해가 있어야 한다고 본다. 해당 survey 논문을 읽으며 기본적인 VLA의 아키텍처와 주요 dataset에 대해 알아봤고, 어떤 세부 분야들이 있고 어떻게 연구가 이루어지고 있는지를 개괄적으로 살펴볼 수 있었다.
다음으로는 이 논문에서 소개하는 efficient VLA 관련 논문들 중 OpenVLA라는 모델을 제안하는 논문을 읽어볼 예정이다. OpenVLA 논문은 해당 survey에서 소개하는 논문들 중에 인용수도 26.1.6. 기준 1433회로 거의 제일 많고(survey의 다른 모델들의 설명에서도 OpenVLA를 언급하는 부분이 꽤 있었다.), 모델이 huggingface에 배포되어 있으며, github에 코드도 있다.