[Paper Review] Fast On-device LLM Inference with NPUs
해당 논문(링크)은 ASPLOS 2025에 publish된 논문으로, 이전에 정리한 HeteroLLM 다음으로 읽어보게 되었다. HeteroLLM은 method 측면에서는 흥미로웠지만 논리적인 허점이 존재하고, 학회에 accpet되어 있지도 않았으며, 코드도 배포되어 있지 않았다. 반면 이 논문은 최근 메이저 학회에 accept되었으면서 코드도 배포되어 있기 때문에 교수님께서 다음으로 읽어볼 논문으로 추천해주셨다.
Abstract
privacy 문제와 mobile-sized model들의 등장에 따라, LLM의 on-device inference는 그 중요성이 커지고 있다. 하지만 특히 prefill phase에서의 inference latency가 그 병목으로 존재하는데, 본 논문에서 제안하는 llm.npu에서는 LLM 연산의 특성을 고려한 효율적인 NPU offloading으로 accuarcy를 유지하면서 prefill latency를 줄인다. llm.npu는 prompt 또는 모델에 대한 re-constructing 기법인 1) chunk-sharing graph, 2) shadow outlier execution, 3) out-of-order subgraph execution으로 이를 달성한다.
llm.npu는 MLLM과 QNN을 활용해 구현되었고, 여러 모델과 device, benchmark에 대해 실험한 결과 inference accuracy를 유지하면서 prefill latency과 energy consumption 측면에서 모든 baseline에 대해 성능 향상을 보였다고 한다.
Background
On-device LLM Inference에서의 prefill latency
Opt, Gemma, Qwen, phi 등 on-device에서 돌아갈 수 있을만한 여러 lightweight LLM들이 개발되어 있지만, inference latency는 여전히 무시하지 못할 수준이다. 논문에서는 이 inference latency에 대한 관찰을 수행했다. 지금까지 decoding phase에 대한 연구가 활발히 진행된 것에 반해(ex. speculative decoding 등), 아래 그래프에서와 같은 전형적인 mobile application들에서 prefill phase가 병목인 것을 알 수 있다(54.2% ~ 98.8%). 수준의 차이는 있지만 CPU를 활용하는 경우와 GPU를 활용하는 경우 모두에서 prefill latency의 비중이 높았고, prompt length가 길어질수록 그 비율이 높아졌다고 한다.
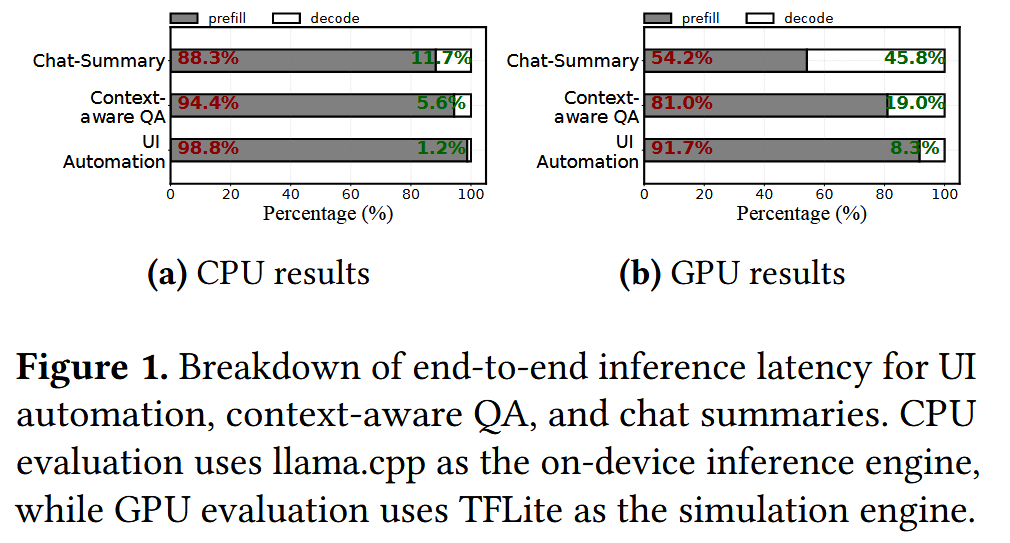
이런 application들에서 prefill phase가 병목이 되는 이유는 아래와 같다.
mobile CPU/GPU는 application logic이나 redering task를 처리하는 것을 주 목적으로 하므로, cloud GPU보다 parallelism capability가 낮다. prefill phase의 computation-bound한 특성에 따라 computation이 병목이 될 수 있다.
mobile LLM task는 personalized, context-aware generation을 위해 long prompt에 대한 처리를 수행하므로 prefill latency가 큰 반면, output length가 대체로 짧아 decoding latency가 적다. 예를 들어, automated email reply의 경우 다양한 사용자 데이터를 고려해야 하고, UI automation의 경우 HTML 파일들과 사용자 명령을 고려해야 한다.
이에 따라 본 연구에서는 on-device LLM의 prefill speed를 확보하는 것을 목표로 한다.
Mobile NPUs
이런 prefill latency를 줄이기 위해, 저자는 mobile SoC(System on Chip)에 포함된 NPU(Neural Processing Unit)를 활용하는 것을 제안한다. NPU는 특히 INT8과 같은 INT-based MatMul 연산에 적합하다고 한다. 아래는 주요 제조사들이 제공하는 NPU 목록이다.

mobile NPU는 SIMD(Single Instruction Multiple Data) architecture를 활용해 성능 향상을 달성하고, 특정 상황(clock frequency 500MHz ~ 750MHz)에서 mobile CPU/GPU보다 energy-efficient하다고 한다. 또한 별도의 physical memory를 가지는 cloud GPU와 달리, SoC의 mobile NPU는 CPU와 physical memory를 공유하므로 별도의 memory copying이 필요하지 않다.
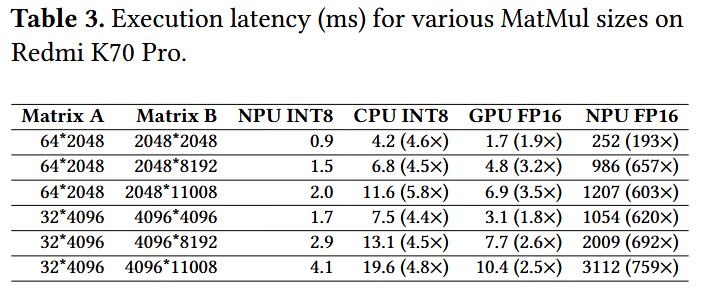
아래 표와 같이 mobile LLM이 주로 수행하는 matrix size에 대한 MatMul 성능을 Redmi K70 Pro에서 실험한 결과, NPU INT8 성능은 CPU INT8, GPU FP16, NPU FP16보다 성능이 뛰어남을 알 수 있다. 즉, NPU의 INT8 SIMD architecture에 의해 NPU는 INT8 MatMul에 대해 최적의 성능을 보인다.
mobile NPU에서 DNN을 돌리는 과정에서는 아래 그림과 같이 NPU environment setting, graph building, graph optimizing, graph executing이 수행되는데, 이 중 특히 graph building과 graph optimizing의 latency가 크다. graph building에서는 모델을 NPU-required intermediate representation으로 변환하고 memory를 할당하는 작업 등이 수행되고, graph optimizing에서는 memory layout 및 execution order 결정, operator fusion 등이 수행된다.

Gap between LLMs and Mobile NPUs
LLM의 prefill phase는 computation-bound하므로, mobile CPU/GPU의 제한된 computing power가 prefill phase에서의 병목이 될 수 있다. 이에 따라 INT(Integer) vector operation에 효율적이고, energy-efficient하고, workload contention이 비교적 적은 NPU를 사용하는 것이 효과적일 수 있다. 하지만 NPU가 LLM inference에 대해 여러 장점을 가지고 있음에도, 상용 mobile NPU에서 LLM inference를 지원하는 시스템은 존재하지 않는다. 그 이유는 아래와 같다.
LLM의 variable-length prompts
현재의 mobile NPU는 efficiency와 최적화 등의 측면에 따라 static computation graph만을 지원한다. 즉, static shape의 prompt만을 처리할 수 있는데, LLM prompt는 dynamic하다는 문제가 있다. 이에 따라 새로운 단순히 shape의 prompt가 입력될 때마다 매번 computation graph를 새로 build/optimize하거나 단순히 padding을 추가해 연산하는 것이 가능하기는 하지만, 두 방식 모두 비효율적이고 비용이 높다. 특히 전자의 경우 ms도 아니고 s 수준의 latency가 발생하므로 CPU 또는 그 이상으로 느려진다고 한다.
LLM quantization 알고리즘들과 mobile NPU design 사이의 괴리
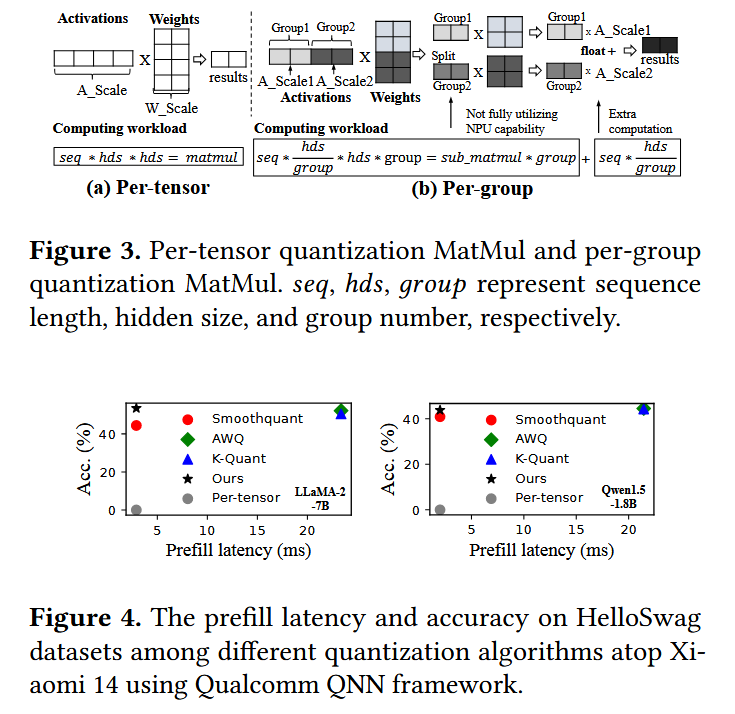
LLM activation에는 outlier가 존재할 수 있으므로 per-tensor 등 granularity가 낮은 quantization 기법을 naive하게 적용하는 경우 accuracy가 떨어지는 문제가 발생할 수 있다. 이에 따라 SOTA LLM들은 주로 group quantization 또는 SmoothQuant 등을 활용한다고 한다. group quantization에서는 activation과 weight를 여러 group으로 나누고, group 별 scaling을 통해 outlier가 다른 group에 영향을 주지 못하도록 한다. SmoothQuant는 outlier를 고려하여 quantization한다.
하지만 NPU는 병렬적인 per-group MatMul(Matrix Multiplcation)과 같은 복잡한 연산은 수행하지 못하므로, 각 group별로 tensor를 쪼개서 각각에 대한 MatMul을 순차적으로 수행한 후 FP(Floating-point) sum operation으로 더해야 한다고 한다(Figure 3). 이 경우 10.7x만큼의 performance overhead가 존재한다. 이에 따라 아래 그래프(Figure 4)에서 확인할 수 있듯이, group quantization을 적용하는 K-Quant, AWQ는 NPU에서 latency가 높다.
또한 SmoothQuant에서는 static하게 outlier를 식별해 처리하므로 3.9% ~ 8.4%의 accuracy 저하가 발생하고, 단순 per-tensor quantization을 적용하는 경우 심각한 accuracy 저하가 발생한다.
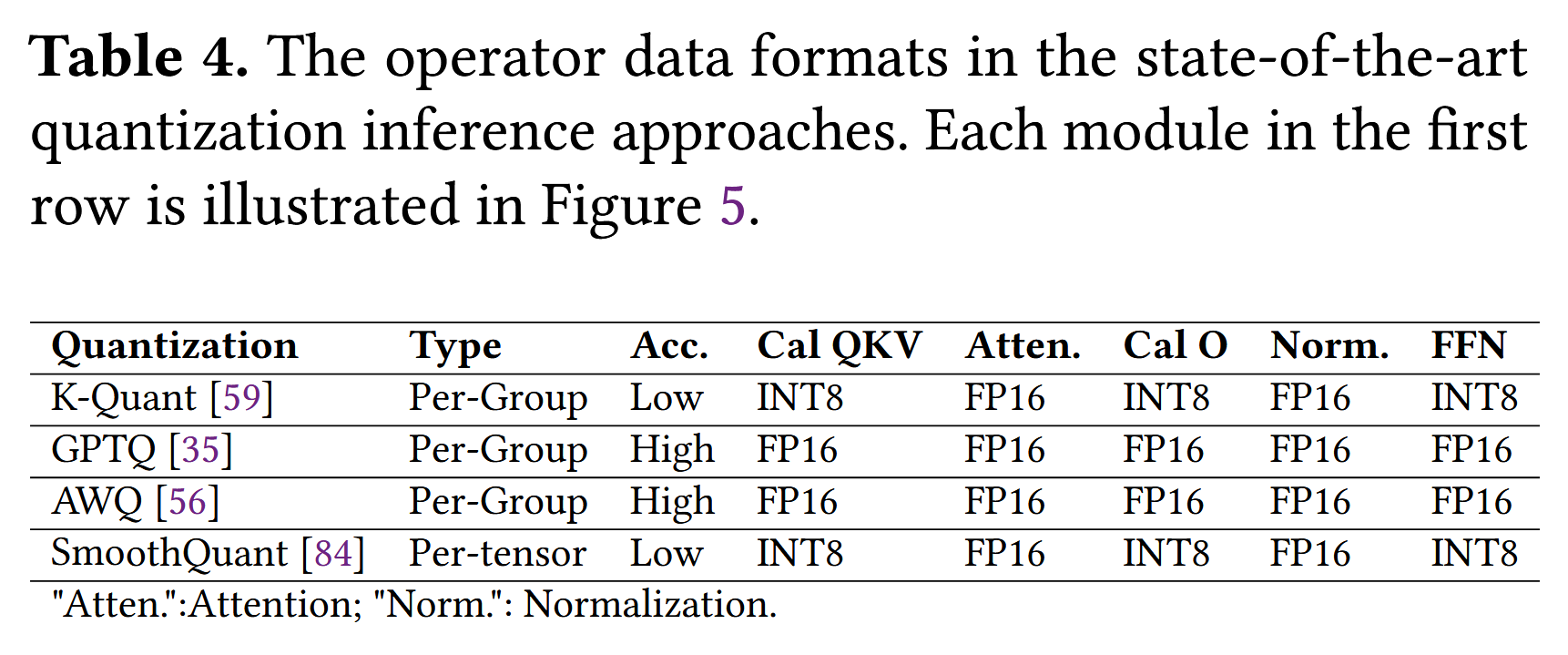
LLM의 FP operations 활용
LLM은 layer normalizatoin, attention 등의 연산을 수행해야 하는데, 해당 부분까지 accuracy 저하 없이 INT-only execution으로 quantization하기 어렵다. 즉, FP operation을 수행하는 부분이 존재하므로 INT 연산이 효율적인 NPU에서는 LLM의 일부 연산들이 효율적으로 수행되기 어렵다.
초창기 NPU는 INT 연산 전용으로 개발되었다고 한다. 반면 현재의 mobile NPU도 energy saving 등의 이유로 INT 연산을 주요 성능 지표로 제시하지만, FP 연산을 지원 또는 강화하는 추세라고 한다.
llm.npu Design
개요
논문에서 제안하는 llm.npu는 효율적인 NPU offloading을 구현한 최초의 LLM inference engine으로, mobile-sized decoder-only LLM에 대해 prefill latency와 energy consumption을 줄이는 것을 그 목표로 한다. llm.npu의 핵심 아이디어는 NPU offloading으로 INT computation을 가속화하고, FP 연산은 CPU/GPU에서 수행하여 accuracy를 유지하는 것이다. 이를 위해 llm.npu는 아래와 같은 세 가지 기법들로 prompt 또는 모델에 대해 prompt/tensor/block level re-constructing을 수행한다.
Chunck-sharing graph execution (prompt level re-constructing)
variable-length prompt들을 다수의 fixed-sized chunk들로 나눠 연산한다. 이때 chunck는 그 크기에 따라 대응되는 pre-built된 subgraph를 가지고 있어 NPU에서 연산이 가능하다. 특히 각 chunk는 chunk-level로 causal하게 연산되는데, 이는 선행 token들만을 고려해 attention 연산을 수행하는 decoder의 insight를 활용한 것으로, data dependancy를 유지한다.
또한 pre-built chunk graph들을 동시에 load하는 것은 memory overhead가 크므로, prompt size에 관련 없는 연산(ex. FFN)들은 각 chunk의 subgraph에서 공유하도록 한다.
이에 따라 variable-length prompt를 NPU에서 효율적으로 처리한다.
Shadow outlier execution (tensor level re-constructing)
outlier들은 추출해 별도의 dense tensor를 구성하여 CPU/GPU에서 병렬적으로 연산하도록 한다.
이때 outlier들에 대한 MatMul을 위해 weight를 CPU memory에 복사함에 따라 증가하는 memory footprint와, CPU/GPU와 NPU 사이의 synchronization overhead가 발생한다. 이에 따라 outlier들이 특정 channel position에서 주로 등장한다는 관찰을 기반으로, 해당 channel들에 해당하는 weight들만 memory에 올려두고 나머지는 disk에 저장했다가 on demand로 가져오도록 한다. 또한 outlier의 importance를 측정하고 그 값에 따라 prune하여 synchronization overhead를 줄인다.
이에 따라 per-tensor quantization을 적용하여 NPU에서 효율적으로 연산하면서도, accuracy를 유지한다.
Out-of-order subgraph execution (block level re-constructing)
각 chunk에 대한 subgraph들을 기존 prompt에서의 순서로 딱 맞춰 실행하는 대신, out-of-order로 CPU/GPU와 NPU에 대해 scheduling한다.
이때 subgraph들에 대한 최적의 실행 순서를 찾는 것은 NP-hard이므로, microsecond-level의 online scheduling 알고리즘을 사용한다.
이에 따라 NPU, CPU 병렬 연산에 따른 bubble을 줄인다.
llm.npu의 동작은 perparation stage와 execution stage로 나누어 볼 수 있다.
Perparation stage
llm.npu는 enhanced per-tensor quantization을 적용한다. 즉, W8A8로 per-tensor quantization을 적용하는데, activation outlier들에 해당하는 weight들을 추출해 둔다.
fixed-length chunk-sharing graph들을 생성한다.
Execution stage
prompt를 입력받으면, llm.npu은 이를 fixed-sized chunk들로 나누고 각각을 causal하게 연산한다. 이때 각 chunk graph들은 다시 subgraph들로 나뉘어지고, data format(INT or FP)에 따라 CPU/GPU와 NPU에 scheduling된다.
linear layer는 기본적으로 NPU에서 INT8로 연산되고, outlier에 대해서는 shadow execution이 적용되어 CPU/GPU에서 FP로 병렬 연산된다.
또한 실행 시에 각 chunk들은 out-of-order로 scheduling된다.
Chunk-sharing graph execution
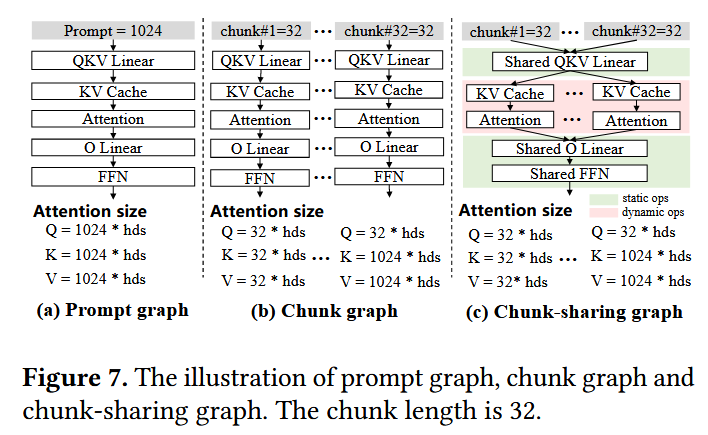
Chunk-wise Prefill?
dynamic prompt length 문제를 해결하기 위해 단순히 padding을 붙일 수도 있지만, 이 경우 flexibility 및 scalability가 떨어지고, 또한 padding 연산에 따른 compute resource 낭비가 발생할 수 있다.
이에 따라 llm.npu에서는 decoder-only 모델 등에서 token들을 causal하게 연산하는 데에서 착안하여, 아래 그림과 같이 prompt를 특정 길이의 chunk들로 나눠 causal하게 연산하고, 남은 부분에는 padding을 추가해 연산하는 Chunk-wise Prefill을 활용한다. 즉, 어떤 chunk에서 attention 연산을 수행할 때는 앞쪽 chunk 모두를 포함시켜 연산한다.
preparation stage에서는 fixed-length의 computation graph들을 pre-build 및 pre-optimize하고, execution stage에서는 prompt를 여러 개의 chunk로 나누고 대응되는 graph들을 활용해 연산한다.
이때 연산이 causal하게 수행되므로 각 chunk는 다른 length의 attention 연산을 처리해야 하고, 개별적인 computation graph를 가져야 한다. 하지만 computation graph는 weight, memory buffer 등을 포함하므로 단순히 chunk-wise하게 처리한다면 memory overhead가 크다. 그래서 논문에서는 더 나아가 chunk-sharing graph를 제안한다.
Chunk-sharing Graph
LLM의 연산은 sequence(chunk) length에 독립적으로 수행되어 chunk별로 공유가 가능한 Static Operator들과(ex. linear, layer normalization), sequence length에 종속적으로 수행되어 공유가 불가능한 Dynamic Operator들이(ex. attention) 있다. 이에 따라 llm.npu에서는 LLM을 static operator들과 dynamic operator들로 나눠, static operator들에 대응되는 subgraph는 한 번만 build 및 optimize하고, dynamic operator들에 대응되는 subgraph는 chunk 마다 개별적으로 build 및 optimize하는 Chunk-sharing Graph를 활용한다. 즉, activation에 대해서 매번 동일한 static operator의 subgraph가 사용되고, dynamic operator에 대해선 적절한 sub-graph가 동적으로 선택된다.
linear layer는 입력 tensor size에 독립적으로 계산되고, layer normalization은 token 내부 값들에 대한 normalization이므로 sequence length에 독립적으로 연산된다.
이에 따라 memory overhead가 크게 줄어들고, scalability가 확보된다. 특히 dynamic operator 중 대부분을 차지하는 attention은 weight를 포함하지 않고 activation buffer만 포함하므로 memory 사용량이 적다.
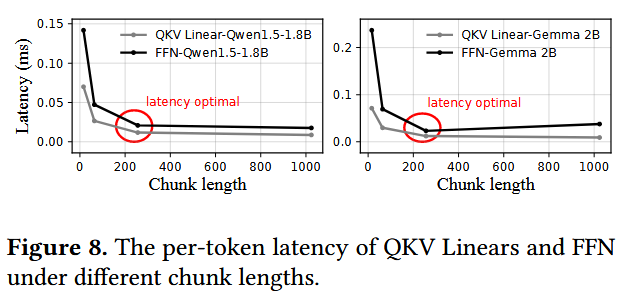
논문에서는 특정 환경에서 memory consumption을 75%까지 줄였다고 한다. 그리고 아래 그림과 같이 Xiaomi 14에 대해 Qwen1.5-1.8B와 Gemma-2B로 실험한 결과 최적의 chunk length는 256이었다고 한다. 물론 이런 profiling은 NPU별로 수행되어야 한다.
Shadow Outlier Execution
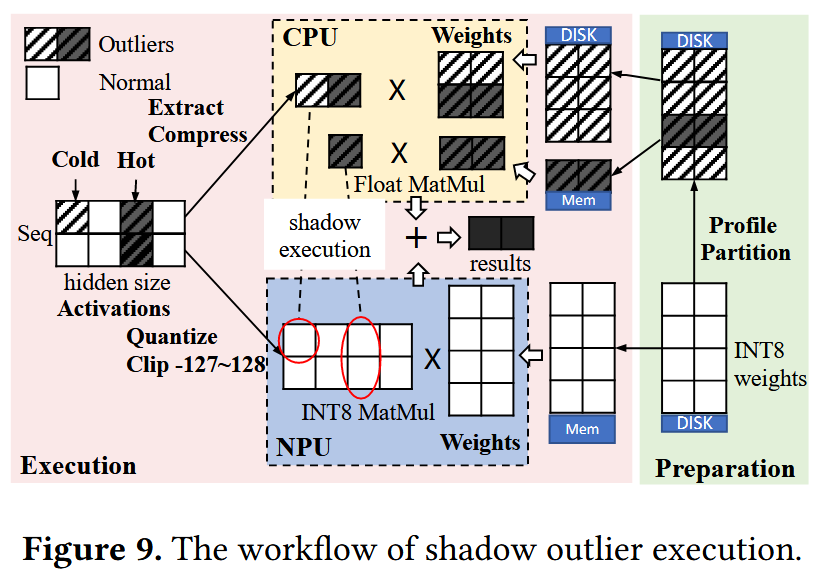
개념 설명
NPU 활용에는 group quantization이 적절하지 않으므로, llm.npu에서는 linear layer에 대해 accuracy 저하가 없는 per-tensor quantization 활용 기법인 Shadow Outlier Execution을 적용한다. shadow outlier execution의 동작은 아래와 같다.
- scale 내부의 값은 NPU에서 INT8 MatMul을 한다. 즉, activation을 scaling factor $s$로 quantize하고 W8A8 MatMul 연산을 한다. 이때 scaling factor $s$는 scale에 대한 threshold로 기능하므로 중요한데, 이는 대규모 corpora에 대한 offline profiling으로 구했다고 한다.
- scale 외부의 값인 outlier들을 따로 추출해 CPU에서 FP MatMul을 한다. 즉, runtime에 outlier들을 추출해 dense한 tensor를 구성하고, 대응되는 weight와 CPU에서 연산한 후 NPU 연산 결과에 병합한다. 이때 실험 결과 outlier는 전체 channel(feature) 중 0.1% ~ 0.3% 수준으로, 아주 sparse하다고 한다. 이에 따라 dense한 tensor로 구성해 CPU에서 연산하는 것이 NPU에서 연산하는 것보다 빠르고, NPU에서 병렬적으로 연산이 수행되므로 hidden된다고 한다.
추가 고려 사항
이런 shadow outlier execution을 실용적으로 적용하기 위해, 아래의 두 가지 사항들도 추가로 고려한다. 즉, llm.npu에서는 자주 사용되는 weight 부분만을 미리 CPU memory에 올려두고, 중요한 일부 outlier들에 대해서만 CPU 연산을 수행한다.
NPU/CPU의 분리된 Memory Space에 따른 Memory Footprint 증가
mobile SoC는 heterogeneous processor들에 대해 unified physical memory를 활용하지만, 각 memory space는 분리되어 있다. 이에 따라 CPU 연산을 위해서는 CPU memory space에 weight copy가 추가로 존재해야 하는데, 전체 weight를 단순 복사한다면 memory footprint가 2배 가까이 증가하게 된다.
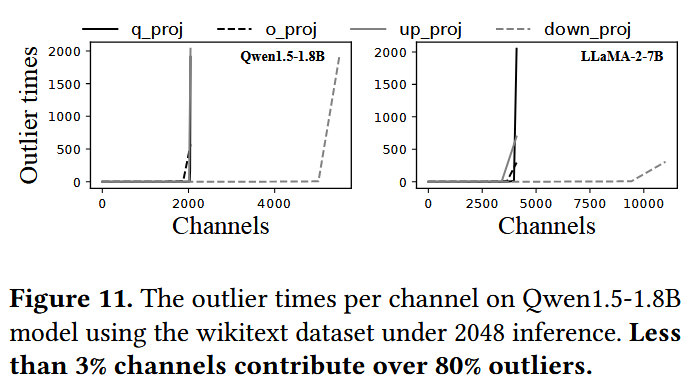
하지만 activation에 대한 관찰에 의하면 아래 그래프와 같이 80% 가량의 outlier들은 3% 정도 되는 특정 channel position(“Hot Channel”)들에서 등장한다. 이에 따라 llm.npu에서는 hot channel들에 대응되는 weight 부분만을 CPU memory space에 저장하고, 나머지는 disk에 저장해뒀다가 필요한 경우 retrieve하여 활용한다. 이때 weight에 대한 retrieval도 outlier 연산과 마찬가지로 NPU execution에 의해 hidden되기 때문에, 효과적으로 memory overhead를 줄일 수 있다.
Synchronization Overhead
NPU와 CPU 각각에서의 연산 이후 이 두 결과를 합치기 위한 synchronization overhead가(latency, energy consumption) 꽤 크다.
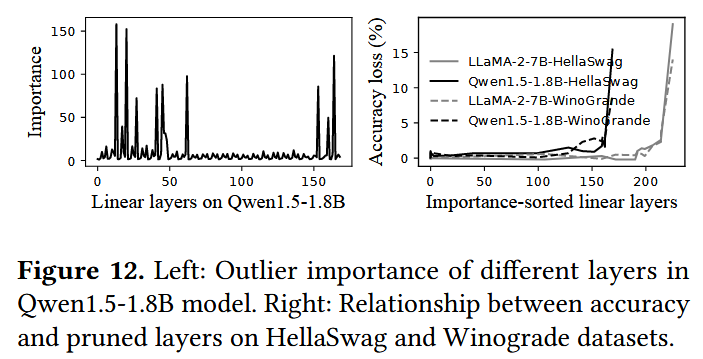
하지만 관찰에 의하면 대부분의 outlier들은 accuracy에 대해 중요도(CPU 연산이 필요한 정도)가 높지 않다. 왼쪽 아래 그래프는 각 layer에 대한 중요도를 나타낸 것으로, 이때의 중요도는 가장 큰 outlier 값을 대응되는 scaling factor로 나눈 값이다. 즉, 중요도가 높을수록 scale에서 더 많이 벗어난 outlier이므로 CPU에서 연산되어야 함을 나타낸다.
이에 따라 llm.npu에서는 scaling factor를 구할 때와 마찬가지로, 대규모 corpora에 대한 offline profiling으로 layer별 중요도를 계산하고, 85% 가량의 중요하지 않은 layer들은 pruning하여 CPU-NPU synchronization overhead를 줄였다고 한다. 여기에서 layer를 pruning했다는 것은 CPU 연산을 별도로 하지 않고 단순히 NPU에서 연산하도록 했음을 말한다.
참고로 오른쪽 아래 그래프를 보면 실제로 중요도가 높은 layer를 pruning했을 때 LLM의 accuracy가 떨어지는 것을 확인할 수 있다.
수식
shadow outlier execution을 수식으로 나타내면 아래와 같다. $x$는 원본 float activation, $w$는 INT8 weight, $s$는 scaling factor, $\odot$는 MatMul, extract()는 activation outlier를 추출하는 함수이다.
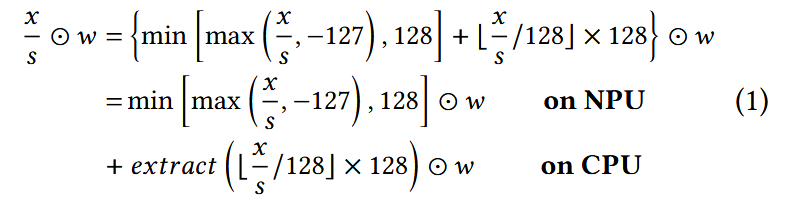
llm.npu는 W8A8 max-min symmetry quantization을 사용해 구현했고 또한 이를 바탕으로 논문에서 설명하고 있지만, 단순히 outlier만 추출해서 따로 연산하는 것이므로, 임의의 per-tensor quantization과 호환될 수 있다고 한다.
Out-of-order Subgraph Execution
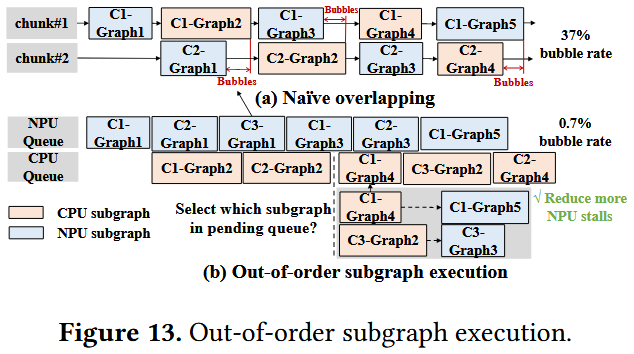
개념 설명
앞서 정리한 것처럼 quantization이 적용되었어도 LLM workflow는 FP operation을 포함하므로, llm.npu에서는 각 연산을 그 종류에 따라 NPU와 CPU/GPU에 적절히 할당하여 처리하도록 한다. 더 구체적으로, layer noramlization, attention, shadow outlier execution은 CPU/GPU에서 연산하도록 하고, linear layer들은 NPU에서 연산하도록 한다.
이때 위의 그림과 같이 naive하게 chunk별로 병렬 실행할 경우 NPU, CPU/GPU 각각의 실행 시간에 차이에 따른 bubble이 존재할 수 있다. 이에 따라 llm.npu에서는 각 chunk에 대한 subgraph들을 out-of-order로 실행하는 Out-of-order Subgraph Execution을 적용한다. 즉, input이 준비된 subgraph는 그 순서에 상관없이 실행하여 bubble을 줄인다.
더 구체적으로 정리하면, llm.npu는 preparation stage에 모든 subgraph의 실행 시간과 dependency를 offline으로 profiling해 두고, execution stage에서는 후보 subgraph의 contribution 값들을 모두 계산해 비교하여 가장 큰 값의 subgraph를 실행시킨다. 여기에는 microsecond-level의 overhead만이 발생한다고 한다.
Dependency 계산 방법
out-of-order subgraph execution은 아래와 같이 두 가지 dependency를 활용하여 특정 연산에 대한 input이 준비되었음(correctness)을 보장한다. 즉, 해당 subgraph가 실행 가능한 상태인지 판단한다. 이때 $G_{i,j}$는 $i$번째 chunk의 $j$번째 subgraph를 나타낸다.
Cross-chunk Dependency
attention 등 이전 chunk들의 값이 필요한 연산의 경우 아래 수식과 같이 이전 chunk들과 현재 chunk에 대해서 직전 subgraph까지의 연산이 완료되어야 수행될 수 있다. 이때 동일 chunk에서 이전 subgraph의 값이 필요한 것은 workflow가 순차적으로 수행되므로 당연하고, 이전 chunk의 값이 필요한 것은 KV cache가 차 있어야 하기 때문인 것으로 보인다.
\[G_{i,j} \leftarrow G_{0,j-1}, G_{1,j-1}, \cdots , G_{i,j-1}\]Intra-chunk Dependency
layer normalization, linear layer, quantize 등 이전 chunk들의 값이 필요하지 않은 연산의 경우 아래 수식과 같이 현재 chunk에 대해서만 직전 subgraph까지의 연산이 완료되면 수행될 수 있다.
\[G_{i,j} \leftarrow G_{i,j-1}\]
Scheduling Strategy
offline에서 여러 subgraph들에 대해 최적의 실행 순서를 찾는 것은 NP-Hard(Traveling Salesman Problem)이다. 이에 따라 llm.npu에서는 prefill phase에서 NPU의 실행 시간이 inference latency의 상당 부분을 차지하는 것을 근거로, NPU stall을 최소화하도록 scheduling하는 online heuristic 알고리즘을 활용한다. 또한 참고로, 논문에서는 mobile processor들은 parallelism과 preemption(선점형)에 적합하지 않다고 주장하면서(논문 몇 개를 인용하고 있다.), 한 번에 하나의 subgraph만 non-preemption(비선점형)으로 수행하는 것을 전제한다.
더 구체적으로는, 아래 수식으로 각 subgraph가 NPU stall을 줄이는 데 얼만큼의 contribution을 가지는지를 계산한다. 즉, llm.npu는 매번 여러 후보 subgraph들의 contribution 값을 비교하여 가장 큰 값을 가지는 것을 선택해 실행한다.
여기에서 $C$는 contribution 값, $g$는 subgraph, $S$는 g가 실행된 직후에 실행될 수 있는 subgraph들의 집합, $T$는 해당 subgraph의 실행 시간이다. g가 CPU/GPU 연산인 경우 이후 실행 사능한 NPU 연산의 실행 시간이 길수록 stall이 적은 것으로 판단하고, g가 NPU 연산인 경우 이후 실행 가능한 CPU/GPU 연산의 실행 시간이 짧을수록 stall이 적은 것으로 판단한다. 논문에 더 자세한 설명은 없지만, CPU/GPU 연산의 실행 시간이 길다면 관련된 NPU 연산에 stall이 발생할 수 있기 때문으로 보인다.
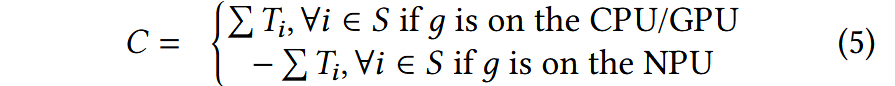
Implementation & Evaluation
개요
llm.npu는 Qualcomm Hexagon NPU에 대해 MLLM(CPU)과 QNN(NPU)을 활용해 구현했다. 또한 device로는 Redmi K70 Pro(Snapdragon 8 gen3, 24GB memory)와 Redmi K60 Pro(Snapdragon 8 gen2, 16GB memory) 각각에 대해 실험했고, 모두 android os 13으로 실험했다. LLM으로는 Qwen1.5-1.8B, Gemma2B, Phi2-2.7B, LLaMA2-Chat-7B, Mistral7B에 대해 실험했다.
사용한 benchmark들은 아래와 같다.
- inference speed 측정 (context-aware generation 성능 확인) : Longbench, 2wikimqa, TriviaQA
- UI action scenario 테스트 : DroidTask
- quantization accuracy 측정 : LAMBDA, HellaSwag, WinoGrande, OpenBookQA, MMLU
실험에서는 TFLite(GPU), MMN(CPU), llama.cpp(CPU), MLC-LLM(GPU)를, PowerInfer-v2(NPU)로 총 5개의 baseline들과의 비교를 수행했다. 참고로 PowerInfer-v2는 NPU를 활용해 prefill phase를 가속화하는 engine인데, LLM에 대한 최적화를 llm.npu만큼 잘 하지는 못했다고 한다. 또한 각 enigne이 실험하려는 LLM들 중 일부만 지원하기도 하므로, 없는 값들은 결과에서 빠져 있다.
metric으로는 inference accruacy, prefill latency, prefill energy consumption, prefill memory consumption, end-to-end inference latency를 활용했다. 각 실험은 3번씩 수행하고, 세 값의 평균을 내서 활용했다고 한다.
또한 실험과 관련하여 아래와 같은 추가적인 디테일들이 존재한다.
별도로 수행한 실험에 의하면 NPU는 동일한 결과의 연산에 대해서도 특정 tensor size이면 더 빠르게 처리할 수 있다고 한다. 이에 따라 llm.npu는 preparation stage에서는 linear layer에 대해 모든 가능한 shape을 profiling하여 최적의 shape을 정한다.
NPU, CPU/GPU에 대해 context switching overhead를 줄이기 위해 중간 값들을 저장하는 shared buffer를 사용했다.
KVCache, RMSNorm, ROPE 등 특정 연산들은 직접 구현했다.
default chunk length는 256, pruning rate는 85% 로 했다.
decoding phase는 쉬운 구현을 위해 CPU로 구현했다. 물론 llm.npu는 임의의 decoding engine과 호환되므로 추후에 구현하면 된다고 한다.
참고로, TFLite를 활용하여 별도의 simulation을 수행했더니 아래의 그래프와 같이 llm.npu의 design에 따라 prefill phase에서는 CPU/GPU 연산이 NPU 연산에 의해 hidden되므로 둘 중에 뭘 사용하든 성능이 거의 동일하고, decoding phase에서는 별도의 design이 존재하지 않으므로 GPU를 사용하면 성능이 향상된다고 한다.

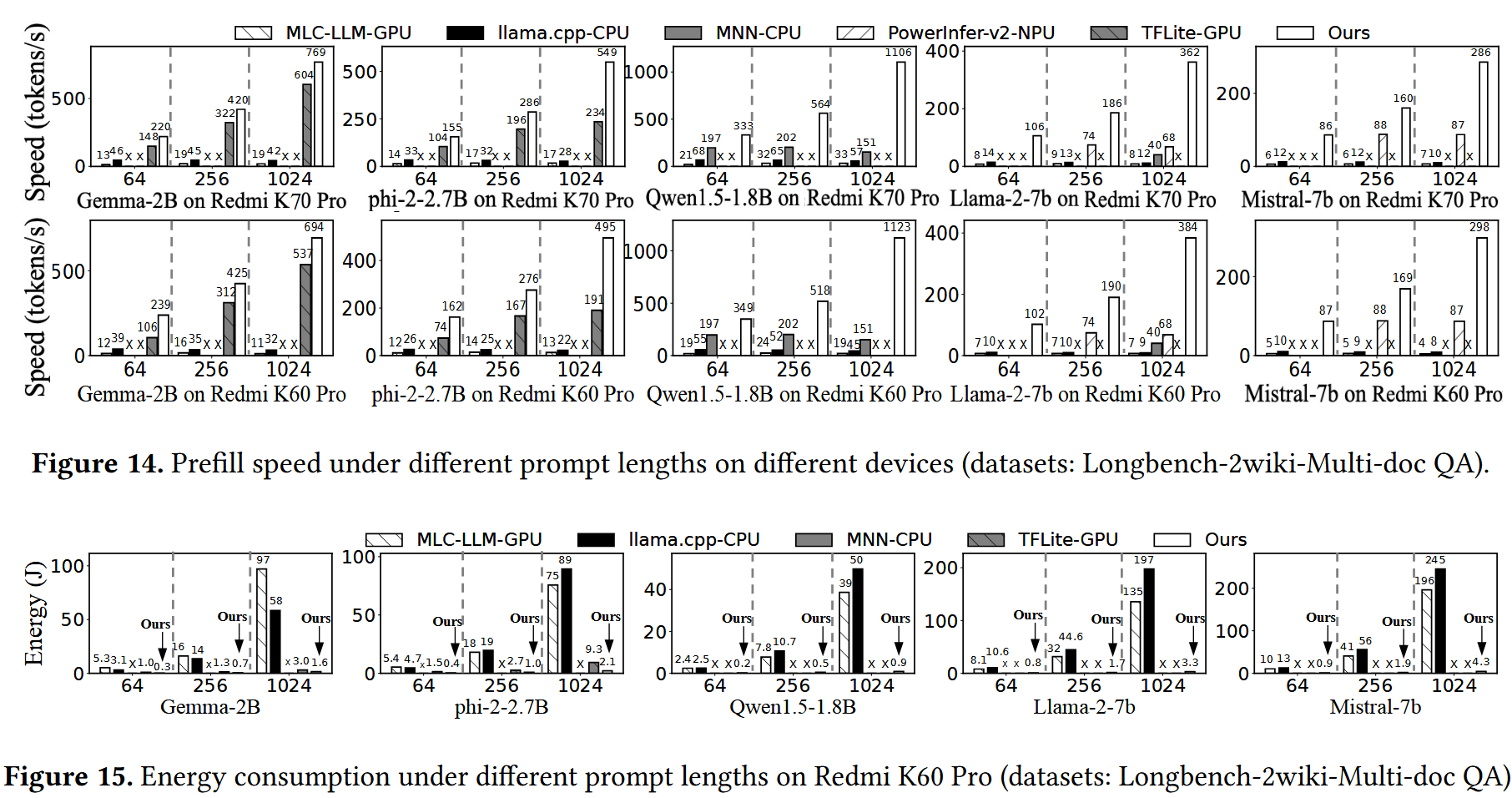
Prefill Performance
prefill performance는 speed와 energy consumption으로 측정했고, 2개의 device와 5가지 LLM에 대해 prompt length를 64, 256, 1024로 해서 수행했다. 이때 여러 dataset에 대해서 prefill preformace 향상이 크지 않아서, LongBench dataset으로 실험했다고 한다. LongBench는 prompt의 길이가 매우 길어서 prefill phase 성능의 비중이 높다고 한다.
그 결과 llm.npu가 모든 경우에서 speed가 높고(1.27x ~ 43.6x), energy consumption이 낮았다고(1.85x ~ 59.52x) 한다. 이는 llm.npu가 앞서 설명한 3가지 기법으로 NPU를 효율적으로 활용했기 때문이라고 한다.
특히 prompt length가 길어질수록 성능 향상이 커졌는데, prompt length가 짧으면 padding에 따른 overhead가 커지고(chunk length를 256으로 했으므로.), out-of-order scheduling에 따른 이점이 적어지기 때문이라고 한다.
End-to-end Performance
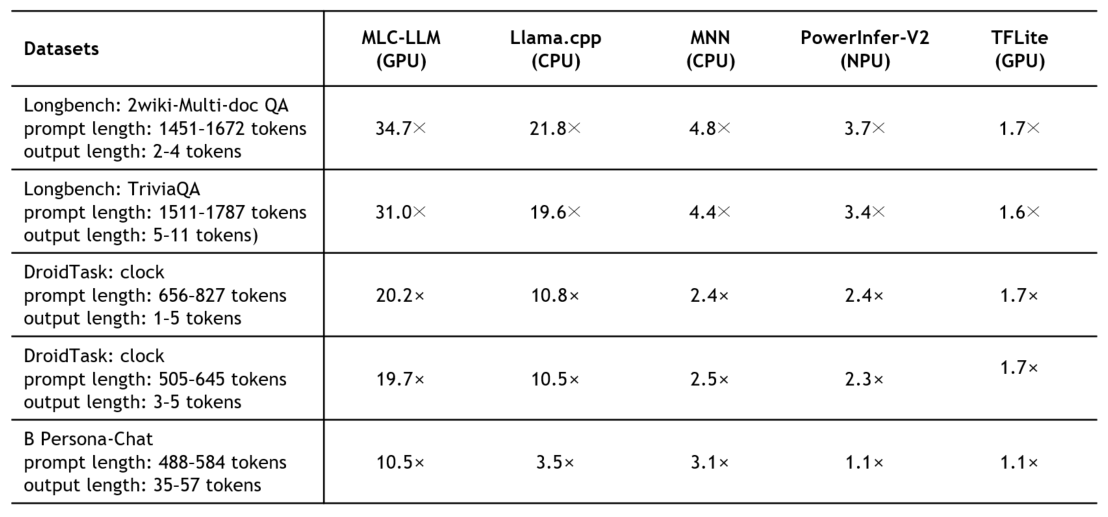
prefill과 decoding 모두를 포함하는 end-to-end performance는 latency로 측정했고, 5가지 LLM에 대해 LongBench, DroidTask, Persona-Chat 성능을 5개의 baseline(inference engine)들과 비교했다. 이는 real-world performance 측정을 위한 것으로, LongBench는 automated email reply에 대해, DroidTask는 UI automation에 대해, Persona-Chad은 chat summary에 대해 성능을 측정한다.
그 결과는 아래와 같다. 실제로는 각 dataset를 5개의 LLM에서 돌졌지만, 값이 너무 많아서 LLM별 성능 향상 정도를 평균낸(geo-mean) 결과만 나타냈다. 즉, 각 값은 해당 dataset에 대해 해당 baseline보다 어느 정도의 성능 향상이 있었는지를 의미한다. 모든 경우에서 llm.npu의 speed가 가장 빨랐다고(1.1x ~ 34.7x) 한다(latency가 적었다.).
end-to-end performance임에도 prefill performance 향상에 따라 전체 성능이 향상되었다고 하고, 여기에서도 대체로 prompt length가 길어질수록 성능 향상 정도가 커졌다고 한다.
이때 llm.npu는 구현의 단순함을 위해 decoding engine은 CPU로 구현되었으므로, decoding phase에서 GPU를 활용하는 TFLite에서는 성능 향상이 적었는데 이는 추후에 개선 가능하다고 한다.
Inference Accuracy
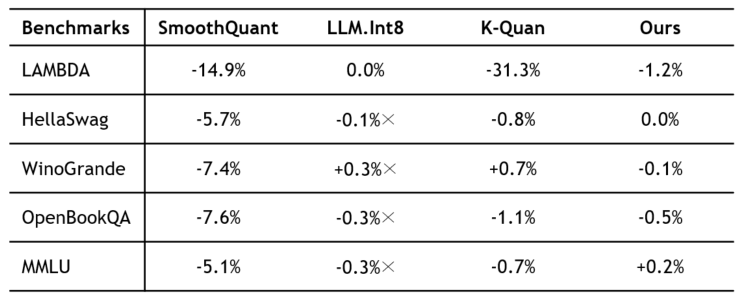
inference accuracy는 5가지 LLM에 대해 5개의 benchmark를 FP16(quantization x), K-Quant(group quantization), SmoothQuant(SOTA per-tensor 기법), LLM.Int8(SOTA outlier 처리 기법)과 비교했다.
그 결과는 아래와 같다. 여기에서도 실제로는 각 benchmark를 5개의 LLM에서 돌렸지만, 값이 너무 많아서 LLM별로 FP16과 비교한 accuracy 변화 정도를 평균낸 결과만 나타냈다. FP16과 비교했을 때 0.0% ~ 1.2% 정도의 accuracy loss만을 보이며 다른 quantization 기법들보다 높은 accuracy를 보였다.
SmoothQuant는 outlier를 static하게 식별해 처리하는데에 반해, llm.npu는 dynamic하게 처리하므로 성능 향상을 보였다고 한다. 또한 group-level quantization을 적용하는 K-Quant에 비해, llm.npu는 element-level로 outlier를 처리하여 성능 향상을 보였다고 한다. 반면 LLM.Int8의 accuracy가 최대 1.2% 정도 더 높은 경우들이 존재하는데, 대신 llm.npu는 NPU 활용에 따른 efficiency를 확보했다고 한다.
참고로 이때 llm.npu의 pruning 비율에 따라 accuracy와 latency는 trade-off 관계에 있다고 한다. 실제로 실험 결과 아래와 같이 pruning을 많이 할수록 latency는 짧아지지만 accuarcy는 떨어지는 것을 확인할 수 있다.

Ablation Study
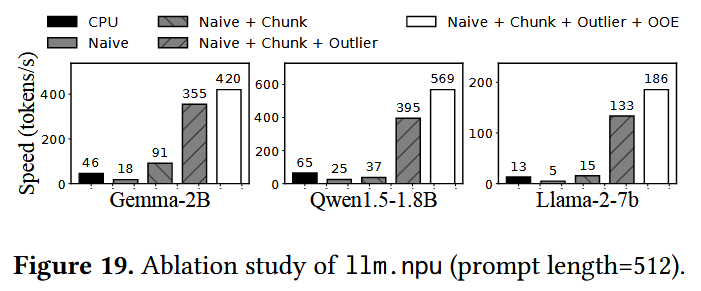
실제로 llm.npu에 적용된 3가지 기법에 대한 ablation study를 수행했더니, 아래와 같이 세 기법 모두 prefill phase에서의 latency 감소에 효과적인 것을 확인할 수 있었다고 한다.
NPU를 naive하게 활용하는 경우 성능이 떨어졌지만, chunk-sharing graph는 1.46x ~ 5.09x의 성능 향상을, shadow outlier execution은 3.91x ~ 8.68x의 성능 향상을, out-of-order subgraph execution은 18% ~ 44%의 성능 향상을 보였다고 한다.
Discussion & Future Work
논문에서는 아래와 같은 discussion들을 제시한다.
mobile GPU는 graphic rendering 등의 작업을 수행해야 할 수 있으므로, LLM inference에 활용할 경우 contention이 많이 발생할 수 있다. 이에 따라 LLM 연산에는 NPU를 주요 accelerator로 활용하는 것이 더 적절할 수 있다.
NPU에서 FP 연산을 지원하도록 하는 것이 최근의 trend임에도 불구하고, NPU를 활용한 LLM 연산에서 INT 연산은 computation performance, memory efficiency, energy saving 측면에서 더 뛰어나므로 여전히 유효할 것으로 판단한다고 한다.
dynamic shape에 대한 처리에 최적화된 하드웨어, 더 큰 NPU cache size, computing unit에서의 mixed precision 지원 등 하드웨어적인 지원이 이루어진다면 llm.npu의 성능은 더욱 향상될 수 있을 것이라고 한다.
llm.npu의 decoding phase는 CPU로 단순하게 구현되었지만, GPU를 활용하고 여러 decoding 관련 알고리즘들을 활용하여 성능을 더 향상시킬 수 있을 것이라고 한다.
결론
llm.npu는 아래의 세 기법을 활용한 NPU offloading을 통해 LLM prefill phase를 효율적으로 가속화하고, energy consumption을 줄인 inference engine이다.
- chunck-sharing graph : computation graph build/optimization 또는 padding에 따른 overhead를 줄인다.
- shadow outlier execution : outlier를 고려한 per-tensor MatMul을 가능하게 한다.
- out-of-order subgraph execution : NPU와 CPU를 병렬적으로 활용하는데에 따른 bubble을 줄인다.
이에 따라 llm.npu는 최대 43.6x의 speed 향상을, 59.5x의 energy saving을 달성한다.
NPU의 static computation graph에 따라 prompt를 fixed-size로 쪼개서 처리한다는 아이디어 자체는 HeteroLLM과 유사하지만, llm.npu는 적절한 quantization 방법을 제시했다. HeteroLLM에서는 NPU에 대해 INT8 연산을 활용하면 accuracy 하락이 존재한다고 주장하며 FP16 연산을 활용했는데, 이는 per-tensor quantization을 naïve하게 적용했기 때문일 수 있을 것 같다. 특히 ablation study의 결과를 확인해 보면 shadow outlier execution의 적용에 따라 speed(tokens/s)가 크게 뛰었다. 즉, accuracy만이 아니라 speed 측면에서도 INT 연산을 활용하는 해당 기법의 유효성이 큰 것을 알 수 있다. 반면 SmoothQuant 등 outlier를 고려하는 다른 quantization 기법을 적용했을 때 accuracy는 떨어지더라도 speed는 증가했을 수 있을 거 같은데(shadow outlier exeuction에서는 offloading하는 등 추가적인 작업이 존재하므로.), 이에 대한 실험 결과는 논문에 없다. SpinQuant라든가 outlier를 잘 고려하면서 더 높은 성능을 보이는 quantization 기법을 대신 적용하면 accuracy를 보존하면서 latency를 더 줄일 수 있을 것 같다.
본 논문에서는 NPU의 FP 연산은 latency가 굉장히 높다고 했음에도 불구하고 HeteroLLM에서는 어떻게 준수한 성능을 보였는지 의문이다.
HeteroLLM에서도 NPU를 활용해 prefill phase 성능은 향상시켰지만, 사실상 decoding phase에서의 성능 향상은 크지 않았다. NPU의 활용은 computation이 병목인 prefill phase에서 특히 유의미한 것으로 보인다.