[Paper Reproducing] llm.npu Reproducing on Snapdragon 8 elite
llm.npu Reproducing
NPU 활용 테스트와, 성능 확인을 위해 이전에 정리한 논문인 Fast On-device LLM Inference with NPUs의 artifact 코드로 reproducing을 시도했다. 해당 논문에서는 mobile SoC에서 NPU를 활용하여 prefill latency를 efficient하게 줄인 llm.npu를 제안한다.
제공된 artifact 코드로 llm.npu를 포함한 여러 engine에 대한 accuracy와 prefill latency를 찍어볼 수 있다. 이때 기본적으로 accuracy는 server의 A100 GPU를 활용해 측정하고, prefill latency는 Redmi K70 Pro 24G(Snapdragon 8 gen 3)에서 측정하도록 되어 있다.
현재의 reproduce에서는 Redmi K70 Pro 24G(Snapdragon 8 gen 3) 대신 RealMe gt7 pro(Snapdragon 8 elite)를 활용하여 llm.npu에 대한 prefill latency 확인을 시도했다. 또한 Qwen1.5-1.8B를 사용하는 것을 default로 코드가 구성되어 있어서 해당 모델에 대해서만 확인했다.
추가로, desktop에서는 wsl에서 실험했다.
Tool 세팅
ADB
ADB(Android Debug Bridge)는 Android device와의 통신을 지원하는 도구로, gt7 pro에서의 실험을 위해 세팅 및 활용했다. ADB는 Desktop과 android device 간에 파일 및 명령어를 주고받거나, desktop에서 android shell을 여는 등의 기능을 지원한다. artifact 코드의 스크립트에서도 adb shell, adb push를 사용해 device에 파일을 전송하고 실행한다. ADB는 유선 또는 무선으로 device에 대한 연결이 가능하다.
유선 연결
powershell에서는 ADB를 설치하고, desktop에 유선으로 device를 연결하고, 휴대폰 개발자 설정에서 ‘USB 디버깅’ 설정을 ON 한 뒤, adb devices를 입력하면 자동 연결된다. 하지만 wsl에서 연결하려면 usb 장치 인식을 위한 별도의 작업이 필요하다. 링크에서 설명하는 것과 같이 powershell에서 usbipd를 사용해 해당 연결을 attach로 지정하면 wsl에서 adb devices를 입력했을 때 연결된다.
연결 및 동작이 잘 되지만, 크기가 큰 파일들을 device에 전송할 때 해당 device의 attach 해제되는 버그가 존재했다. 구글링 결과 ADB를 유선으로 사용할 때 동일한 문제가 존재했다는 글들이 여럿 있었고, ADB를 무선으로 사용했더니 해결됐다.
무선 연결
ADB를 설치하고, 휴대폰 개발자 설정에서 ‘무선 디버깅’ 설정을 ON 한 뒤, ‘무선 디버깅’ 설정에서 ‘기기 페어링’ 항목의 ip 주소, port 번호, 페어링 코드를 활용해 desktop과 devices를 페어링하고, 이후 ‘무선 디버깅’ 설정의 ip 주소, port 번호를 활용해 해당 device에 연결할 수 있다.
QPM
artifact 코드의 README를 보면 QNN과 Hexagon SDK를 다운받아 활용하는데, 이를 QPM(Qualcomm Package Manager 3)로 수행하라고 되어 있다. 하지만 다운로드를 위해 Qualcomm 계정으로 QPM 웹사이트에 로그인하면 항상 401 access denied만 뜨는 버그가 발생했다.
그래서 qualcomm 홈페이지에서 company verification 요청, Qualcomm tools 팀에 support 요청, forum에 질문 글 게시 등을 시도했지만 해결되지 않았다. 과거에 QPM을 사용했었던 연구실 선배한테 연락해서 확인했더니, 선배 계정에서는 401이 안 떠서 QPM을 대신 다운로드해 전달받았다. 전달받은 QPM을 사용하여 특전 버전의 QNN과 Hexagon SDK를 설치할 수 있었다.
QPM으로 소프트웨어 다운로드 중에 unexpected error가 발생하는 문제가 있었는데, QPM이 설치된 디렉토리에 가서 setup 스크립트를 확인해보니 /var/tmp/qcom/qik/logs에 로그를 저장하고 있어서, 해당 로그를 읽으며 디버깅했다. 소프트웨어 저장 디렉토리 경로(–path)를 상대경로로 해서 뜨는 에러였고, 절대경로로 지정했더니 해결됐다.
Snapdragon Profiler
QPM으로 Snapdragon Profiler를 설치해 profiling에 사용했다. profiler 설치 후에 README에 따라 환경 세팅을 수행했고, 디렉토리 내부의 run 스크립트로 profiler를 실행할 수 있었다.
Snapdragon Profiler를 실행하면 device를 자동으로 인식하고, 해당 device에서도 Snapdragon Profiler에 대한 설치가 자동으로 시작되는데, device에서 install을 confirm해야 설치된다. device에서의 설치도 끝나면 desktop의 profiler에서 profiling이 가능하다. 이때 gt7 pro를 무선으로 연결하고 시도하면 Snapdragon profiler 설치는 잘 되지만, timeout되며 연결은 되지 않는 문제가 있었는데, 유선으로 바꿨더니 연결도 잘 됐다.
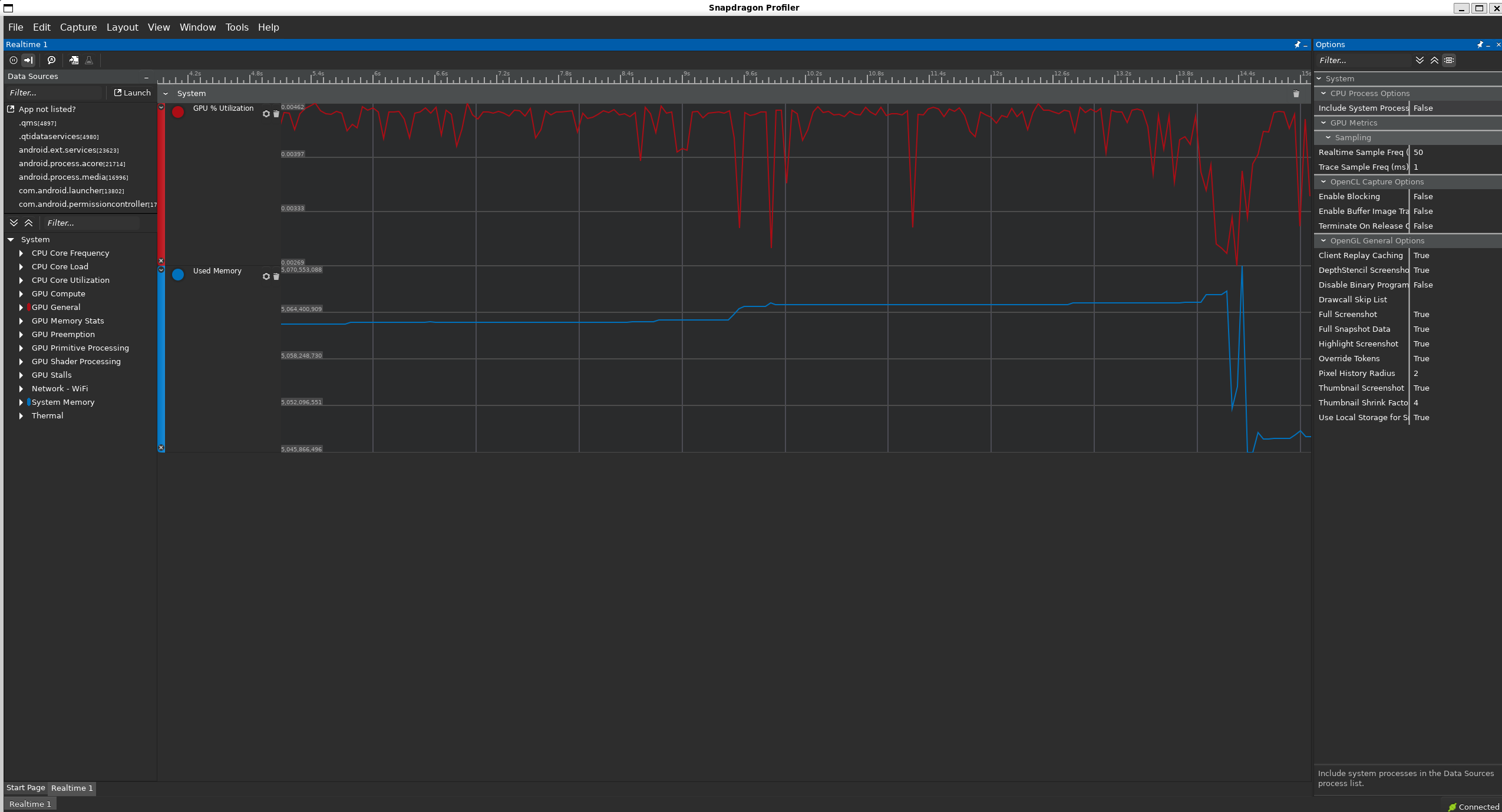
아래와 같이 runtime에서 하드웨어 정보를 profiling할 수 있다. 다만 원래는 NPU 자체에 대한 정보를 확인하려고 했으나, gt7 pro에서는 NPU 관련 정보가 확인되지 않았다(rooting이 되지 않았기 때문인 것 같다.). 그래서 memory usage와 GPU utilization으로 NPU 사용을 간접적으로만 확인했다.
진행 과정
artifact 코드에 포함된 README를 따라 환경 세팅을 한 뒤, build 스크립트 및 run 스크립트를 실행하면 결과가 출력되도록 코드가 구성되어 있다(대부분은 mllm 코드이다.). 더 구체적으로는 환경설정과 실행을 아래의 단계에 따라 수행해야 한다.
- QPM으로 QNN, Hexagon SDK를 다운받고, llm.npu 디렉토리의 특정 위치에 붙여넣는다.
- 몇몇 환경변수들을 세팅한다.
- 일부 operation 소스 코드를 build해 .so 파일들을 생성한다. 해당 makefile은 QNN, Hexagon SDK를 활용한다.
- build 스크립트로 메인 실행 코드를 build해 메인 실행 파일을 생성한다. build 스크립트는 내부적으로 QNN을 활용한다.
- run 스크립트로 메인 실행 파일, mllm 모델, mllm 모델 vocab, QNN .so 파일, operation 코드로 생성한 .so 파일을 ADB를 사용해 device로 전송하고, device에서 메인 실행 파일을 실행한다.
최신 QNN, Hexagon SDK 사용하기
내가 사용하는 SoC는 Snapdragon 8 elite mobile이어서, 8 gen 3를 사용한 논문의 버전대로 QNN, Hexagon SDK를 사용하면 아래와 같은 오류가 뜬다. 실제로 QNN 디렉토리를 확인해 봐도 v75까지는 있는데 8 elite의 NPU인 v79에 대한 디렉토리가 존재하지 않는다. 즉, v79에 호환되는 최신 버전의 QNN, Hexagon SDK를 사용해야 한다. QPM으로 QNN은 2.37.0.250724로, Hexagon SDK는 6.3.0.0로 설치했다.
1
[ ERROR ] <E> Dsp startup: SoC model (SnapdragonModel) is unknown
물론 단순히 새로운 버전의 QNN, Hexagon SDK를 설치해서 바로 활용하는 경우, 해당 코드는 이전 버전 기준으로 작성되었으므로 아래의 에러가 뜨며 실행이 안된다. 내부 파일들을 뜯어보며 호환되도록 수정해야 한다.
1
[ ERROR ] QnnDsp <E> Stub lib id mismatch: expected (v2.37.0.250724175447_124859), detected (v2.25.5.240807173323_97754)
run 스크립트 기준으로 버전 맞추기
run 스크립트를 보면 실행에 어떤 파일들이 필요한지 알 수 있으므로, 해당 스크립트 기준으로 각 파일의 버전을 맞췄다. QNN, Hexagon SDK에 종속적이어서 수정을 고려해야 하는 파일들은 아래와 같다.
- 메인 실행 파일 : build 시에 QNN을 활용한다. QNN 버전이 바뀌었으므로 새롭게 build해야 한다.
- QNN .so 파일들 : QNN 파일을 그대로 가져다 쓴다. 이 파일들은 run 스크립트에서 단순히 v75를 v79로 바꾼 경로를 사용하기만 하면 된다.
- build해야 하는 operation .so 파일들 : QNN, Hexagon SDK를 활용하는 make로 build한다. make를 다시 해줘야 한다.
몇몇 버그를 해결하며 메인 실행 파일은 다시 build했고, QNN .so 파일들은 run 스크립트에서 v79에 대한 것으로 경로명을 바꿔줬다.
Operation들 make로 다시 build하기
src/backends/qnn/LLaMAOpPackageHtp에 있는 operation들을 make로 다시 build하기 위해 makefile을 뜯어보고, v75에 대한 코드를 참고해 makefile에 v79에 대한 코드를 추가한 뒤 operation들을 다시 build했다.
또한 make 시에 일부 operation 파일에 대해 아래와 같은 오류가 떴는데, QNN 버전이 바뀌면서 일부 메소드명이 달라진 것이어서 메소드명을 최신 버전으로 수정해줬다.
1
2
3
4
5
...
src/ops/IRoPE.cpp:149:70: error: no member named 'get_interface_scale' in 'Tensor'
149 | float value = (in_value-128) * (cos_value-128) * cos.get_interface_scale() - (in_value_2-128) * (sin_value-128) * sin.get_interface_scale();
| ~~~ ^
...
수정한 run 스크립트
우선 버전에 맞게 수정한 결과 run 스크립트는 아래와 같다. 즉, /data/local/tmp/mllm에 파일들을 올린 뒤 실행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
#!/bin/bash
adb shell mkdir /data/local/tmp/mllm
adb shell mkdir /data/local/tmp/mllm/bin
adb shell mkdir /data/local/tmp/mllm/models
adb shell mkdir /data/local/tmp/mllm/vocab
adb shell mkdir /data/local/tmp/mllm/qnn-lib
adb push ../vocab/qwen_vocab.mllm /data/local/tmp/mllm/vocab/ # 모델 vocab
adb push ../vocab/qwen_merges.txt /data/local/tmp/mllm/vocab/ # 모델 merge 파일
adb push ../bin-arm/main_qwen_npu /data/local/tmp/mllm/bin/ # 메인 실행 파일
adb push ../models/qwen-1.5-1.8b-chat-int8.mllm /data/local/tmp/mllm/models/ # 모델
adb push ../models/qwen-1.5-1.8b-chat-q4k.mllm /data/local/tmp/mllm/models/ # 모델
# check if qnn env is set up
if [ -z "$QNN_SDK_ROOT" ]; then
echo "QNN_SDK_ROOT is not set"
exit 1
else
echo "QNN_SDK_ROOT is set to $QNN_SDK_ROOT"
fi
LIBPATH=../src/backends/qnn/qualcomm_ai_engine_direct_220/ # 디렉토리명은 220이지만 이름만 그렇고 최신 버전(237)을 넣어 놨다.
ANDR_LIB=$LIBPATH/lib/aarch64-android
OP_PATH=../src/backends/qnn/LLaMAOpPackageHtp/LLaMAPackage/build
DEST=/data/local/tmp/mllm/qnn-lib
adb push $ANDR_LIB/libQnnHtp.so $DEST # QNN .so 파일
adb push $ANDR_LIB/libQnnHtpV79Stub.so $DEST # QNN .so 파일
adb push $ANDR_LIB/libQnnHtpPrepare.so $DEST # QNN .so 파일
adb push $ANDR_LIB/libQnnHtpProfilingReader.so $DEST # QNN .so 파일
adb push $ANDR_LIB/libQnnHtpOptraceProfilingReader.so $DEST # QNN .so 파일
adb push $ANDR_LIB/libQnnHtpV79CalculatorStub.so $DEST # QNN .so 파일
adb push $LIBPATH/lib/hexagon-v79/unsigned/libQnnHtpV79Skel.so $DEST # QNN .so 파일
adb push $OP_PATH/aarch64-android/libQnnLLaMAPackage.so $DEST/libQnnLLaMAPackage_CPU.so # make로 build한 operation .so 파일
adb push $OP_PATH/hexagon-v79/libQnnLLaMAPackage.so $DEST/libQnnLLaMAPackage_HTP.so # make로 build한 operation .so 파일
# if push failed, exit
if [ $? -ne 0 ]; then
echo "adb push failed"
exit 1
fi
echo "prompt = 64."
adb shell "cd /data/local/tmp/mllm/bin && export LD_LIBRARY_PATH=/data/local/tmp/mllm/qnn-lib && export ADSP_LIBRARY_PATH=/data/local/tmp/mllm/qnn-lib && ./main_qwen_npu -s 64 -c 0"
echo "prompt = 256."
adb shell "cd /data/local/tmp/mllm/bin && export LD_LIBRARY_PATH=/data/local/tmp/mllm/qnn-lib && export ADSP_LIBRARY_PATH=/data/local/tmp/mllm/qnn-lib && ./main_qwen_npu -s 256 -c 0"
echo "prompt = 1024."
adb shell "cd /data/local/tmp/mllm/bin && export LD_LIBRARY_PATH=/data/local/tmp/mllm/qnn-lib && export ADSP_LIBRARY_PATH=/data/local/tmp/mllm/qnn-lib && ./main_qwen_npu -s 1024 -c 1"
추가 디버깅 사항들
실제로는 여기에 정리한 것 외에도 자잘한 버그가 여러 개 있었는데, 비교적 시간을 많이 쓴 것만 간단히 정리한다.
tensor name already exists in the graph 오류 디버깅
build가 오류 없이 잘 됐는데, run 스크립트에서 메인 실행 파일을 실행하면 런타임에 아래와 같은 오류가 떴다.
1
2
3
4
5
[ ERROR ] QnnDsp <E> Tensor name InceptionV3_InceptionV3_Conv2d_1a_3x3_Conv2D_stride already exists in the graph.
[ ERROR ] QnnModel::addTensor() Creating tensor for node: model.layers.0.self_attn.k_proj.linearint8, tensorName: InceptionV3_InceptionV3_Conv2d_1a_3x3_Conv2D_stride.
[ ERROR ] QnnModel::addNode() addTensor() failed for tensor param InceptionV3_InceptionV3_Conv2d_1a_3x3_Conv2D_stride on node model.layers.0.self_attn.k_proj.linearint8.
[ ERROR ] qnnModels_[qnnModelIndex_].addNode( QNN_OPCONFIG_VERSION_1, name.c_str(), packageName.c_str(), nodeType.c_str(), paramsPtr, params.size(), inputTensorNames, inputTensorNames.size(), outputTensors.data(), outputTensors.size() ) expected MODEL_NO_ERROR, got MODEL_TENSOR_ERROR
Segmentation fault
vsc에서 해당 오류 메시지를 검색해 보니, 여러 파일이 검색됐는데 그 중 오류가 발생한 가장 유력한 파일은 op/QNNLinearINT8.cpp의 QNNLinearINT8::setup()이었다. 코드를 보니 내부적으로 graph에 해당 연산을 추가하는데, operation name이 문자열로 하드코딩되어 있어서 생긴 문제였다. linear layer가 당연히 여러 개 존재하기 때문에, 각 layer에 대해 graph에 연산을 추가하다 보니 operation name이 중복되서 에러가 뜬 것이다.
단순히 operation name 문자열에 현재 layer 이름 문자열을 concat해 해결했고, 출력 찍어보면 전부 setup이 잘 되는 것을 확인할 수 있었다.
merge file is broken 오류 디버깅
build가 오류 없이 잘 됐는데, run 스크립트에서 메인 실행 파일을 실행하면 런타임에 merge file is broken이라는 에러가 뜨는 버그가 있었다.
vsc에서 해당 오류 메시지를 검색해 보니, tokenization_qwen.hpp의 QWenTokenizer에서 해당 메시지가 뜬 것이었다. merge_file의 stream에 대해 문제가 있으면 오류가 뜨게 되어 있었다. 검색 결과 QwenTokenizer는 LibHelper::setup()에서 호출하고 있었고, LibHelper::setup()은 main_qwen_npu.cpp(메인 코드)에서 호출하고 있었는데, main_qwen_npu.cpp에서는 vocab/qwen_merges.txt를 열도록 되어 있었다. 즉, qwen_merges.txt가 있어야 하는데 run 스크립트에서 해당 파일을 push하지 않았기 때문에 stream 오류가 뜬 것이다. 제공된 run 스크립트에 문제가 있었던 것 같다.
해당 경로에 qwen_merges.txt 파일도 추가로 push 해줬더니 해결됐다.
결과
코드에서 예시로 나와있는 문자열로 실험한 결과 논문 정도는 아니지만 비슷한 수준의 성능이 나온다. sequence length 64, 256, 1024에 대한 prefill latency는 각각 201.087ms, 487.811ms, 1010.18ms였다. 즉, speed(tokens/s)는 각각 318.27, 524.79, 1013.68이다. 논문에서는 speed(tokens/s)가 각각 333, 564, 1106이었는데, 실행할 때마다 값이 조금씩 다른 것을 감안하면 납득할 만한 수치인 것으로 보인다. 다만 논문에서 사용한 SoC는 hexagon v75인 반면, 여기에서 사용한 것은 hexagon v79이므로 실제로는 성능이 비교적 낮을 수 있다.
물론 NPU 자체의 utilization 수준은 확인할 수 없었지만, 해당 실험 중에 GPU utilization을 찍어보니 거의 0에 가까운 것을 확인할 수 있었다. 또한 논문에서 주장하는 정도의 성능이 나온 것으로 보아 NPU를 적절히 활용하고 있는 것 같다.
아래는 sequence length 64에서의 출력 예시이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
(base) wnsx0000@aica:~/jhun/llmnpu/llm.npu-AE-ASPLOS25/performance_results/llm.npu/scripts$ ./run_qwen_npu.sh
prompt = 64.
Load model: 1.54524 s
Load model: 3.43155 s
prompt_length: 64
[Q] <|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Give me a short introduction to large language model.<|im_end|>
<|im_start|>assistant
[A]
load and setup begin.
load and setup finish.
Begin inference.
prefill time: 201.087ms
A large language model is a type of artificial intelligence (AI) system that is designed to generate human-like text based on input provided by the user These models are typically trained on large datasets of text, such as books, articles, or web pages, and use a combination of natural language processing (NLP) techniques to analyze the text and generate coherent and grammatically correct sentences.
The goal of a large language model is to produce text that is not only fluent and coherent but also relevant to the input provided by the user This is achieved by using a combination of techniques such as machine learning algorithms, neural networks, and rule-based systems The models are trained on the input data using a large number of training examples, which allows them to learn the patterns and relationships between words and phrases in the language.
Large language models are widely used in a variety of applications, including natural language processing tasks such as text classification, question answering, and language translation They are also used in chatbots, virtual assistants, and other applications where the user can interact with the model to generate text based on their input.
One of the key advantages of large language models is their ability to generate text that is highly adaptable to a wide range of input formats This makes them ideal for tasks such as text summarization, text generation, and text classification, where the input can be in the form of paragraphs or sentences However, the downside of large language models is that they can also produce text that is highly biased and may contain errors or inappropriate content, which can be problematic in certain applications.
Overall, large language models are a powerful tool for generating human-like text, and their use is expected to continue to grow in the coming years as AI technology continues to advance<|im_end|>
...
여기에서는 artifact 코드 중에 llm.npu의 prefill speed만을 찍어봤고, 다른 baseline engine들과 여러 모델, accuracy 등은 찍어보지 않았는데, 비슷한 과정을 거치며 확인이 가능할 듯하다.
논문에 대한 reproducing은 처음 수행해 봤는데, NPU에 대한 구체적인 profiling은 불가능했지만 mllm 기반의 코드를 읽고 수정해볼 수 있는 괜찮은 기회였다. 또한 소프트웨어 버전을 맞추면서 일부 코드를 수정하는 등의 디버깅을 꽤 했는데, 그런 디버깅 과정에 대해서도 더 능숙해질 수 있었다. 이번엔 android device에서 코드를 돌리느라 별도의 디버깅 툴을 쓰지는 않았는데, 써서 breakpoint 찍고 했으면 더 쉬웠을 거 같다.