[Project] ToTRM : Tree-of-Thought Tiny Recursive Model
본 포스트에서는 2025년 3학년 2학기 데이터사이언스(김창훈)와 머신러닝(김창훈) 수업에서 진행한 프로젝트인 ToTRM에 대해 설명한다. 이 프로젝트는 3주 가량 혼자서 방향성을 정하고 실험하며 진행했다. 해당 프로젝트에서 TRM, ToT, FiLM 등에 대해 처음 접했고, 직접 pretraining 및 fine-tuning을 수행했다. 이 과정에서 모델 아키텍처의 각 부분에서 최선의 method가 무엇일지 결정하고, hyperparameter를 조정하며 성능을 향상시켜보는 경험을 했다. 또한 수업 마지막에 프로젝트에 대한 포스터 발표가 있어서 포스터도 제작했었는데, 당시에 그렸던 model architecture 관련 그림도 활용해서 이 포스트에 정리했다.
간단하지만 나름 재미있는 프로젝트였으며, 연구 과정과 주제에 대한 motivation을 논리적으로 이끌어 나가는 것의 중요성과, 컴퓨팅 파워가 연구 속도에 미치는 영향을 여실히 깨닫게 됐다.
주제
본 프로젝트에서 제안하는 ToTRM(Tree-of-Thought Tiny Recursive Model)은 LLM의 CoT 기법 중 하나인 ToT(Tree-of-Thought) 기법을 TRM 아키텍처에서 구현한다.
현재의 LLM(Large Language Model)들은 CoT(Chain-of-Thought)와 같은 프롬프팅 기법을 통해 복잡한 추론 문제를 해결하지만, 수십억~수천억 파라미터의 거대한 크기와 높은 계산 비용이 필요하다.
삼성 SAIL 몬트리올의 연구진이 2025년 10월 arxiv에서 제안한 TRM(Tiny Recursive Model)은 7M 파라미터의 작은 크기로 latent space에서의 CoT를 구현하여 기존 LLM의 성능을 몇 가지 어려운 task에서 능가하지만, basic한 형태의 CoT만 활용하여 복잡한 문제 해결 능력에 한계가 있다.
ToTRM은 Sudoku Extreme 데이터셋에서 단 9%의 추가 파라미터를 사용해 TRM 대비 75%에서 80%로 5%p의 accuracy 개선을 달성한다. 또한 ablation study를 통해 각 component의 효과를 검증하였다. 이를 통해 작은 모델도 올바른 구조 설계로 복잡한 추론이 가능함을 입증하고, LLM 없이도 효율적인 추론 시스템 구축 가능성을 제시한다.
배경
TRM
TRM(Tiny Recursive Model)은 7M 정도로 작은 크기의 신경망으로, 복잡한 추론 문제를 해결하기 위한 재귀적 추론 모델이다. 해당 paper에서는 TRM이 model size가 굉장히 작음에도 불구하고 sudoku extreme, maze hard, ARC-AGI-1, ARC-AGI-2과 같은 벤치마크에서 HRM과 deepseek r1, Claude 3.7, o3, gemini 2.5 pro 등의 cloud 기반 LLM을 능가했다고 주장한다.
TRM 아키텍처
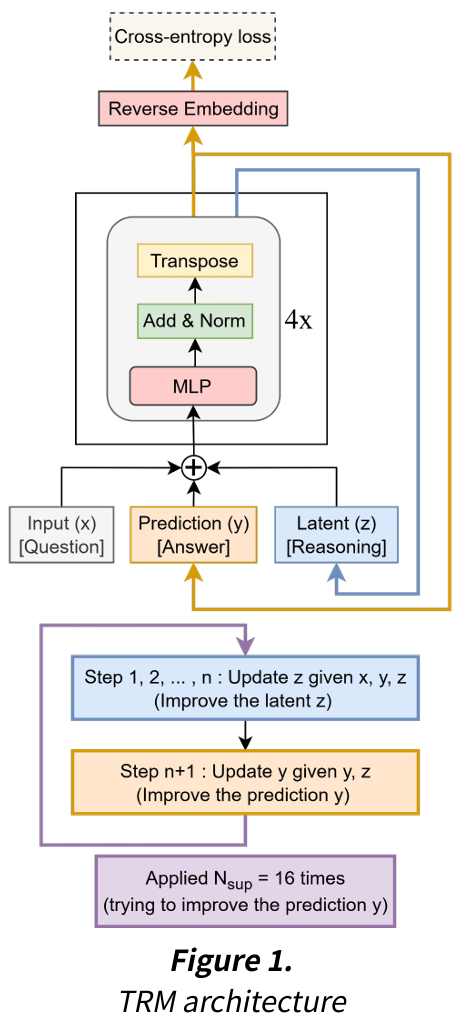
TRM은 transformer block들로 구성된 하나의 network를 사용해, z와 y를 recursive하게 계산한다. 이때 y는 high-level embedding으로 실제 정답을 예측하는 embedding이고, z는 low-level embedding으로 reasoning을 위한 중간 embedding이다.
TRM은 다음과 같이 recursive하게 추론 및 학습된다.
- H_cycles번의 high-level recursion으로 y를 계산한다. (ex. 3회)
- 각 H_cycle마다 L_cycles번의 low level recursion으로 z를 계산한다. (ex. 6회)
- H_cycles번의 high-level recursion 중 마지막 H_cycle에 대해서만 backpropagation 수행한다.
그 아키텍처는 다음 그림과 같다. 이렇게 출력을 입력으로 넣는 아키텍처를 가지므로, layer 수준의 CoT(Chain-of-Thought)를 구현했다고 볼 수 있고, 실제로 TRM paper에서도 그렇게 설명하고 있다. 하지만 TRM에서 구현하는 CoT는 가장 basic한 형태의 선형적 CoT 기법으로, 본 프로젝트에서 제안하는 ToTRM은 더 고도화된 LLM의 CoT 기법을 TRM 아키텍처에서 구현한다.
Tree-of-Thought
CoT(Chain-of-Thought)란?
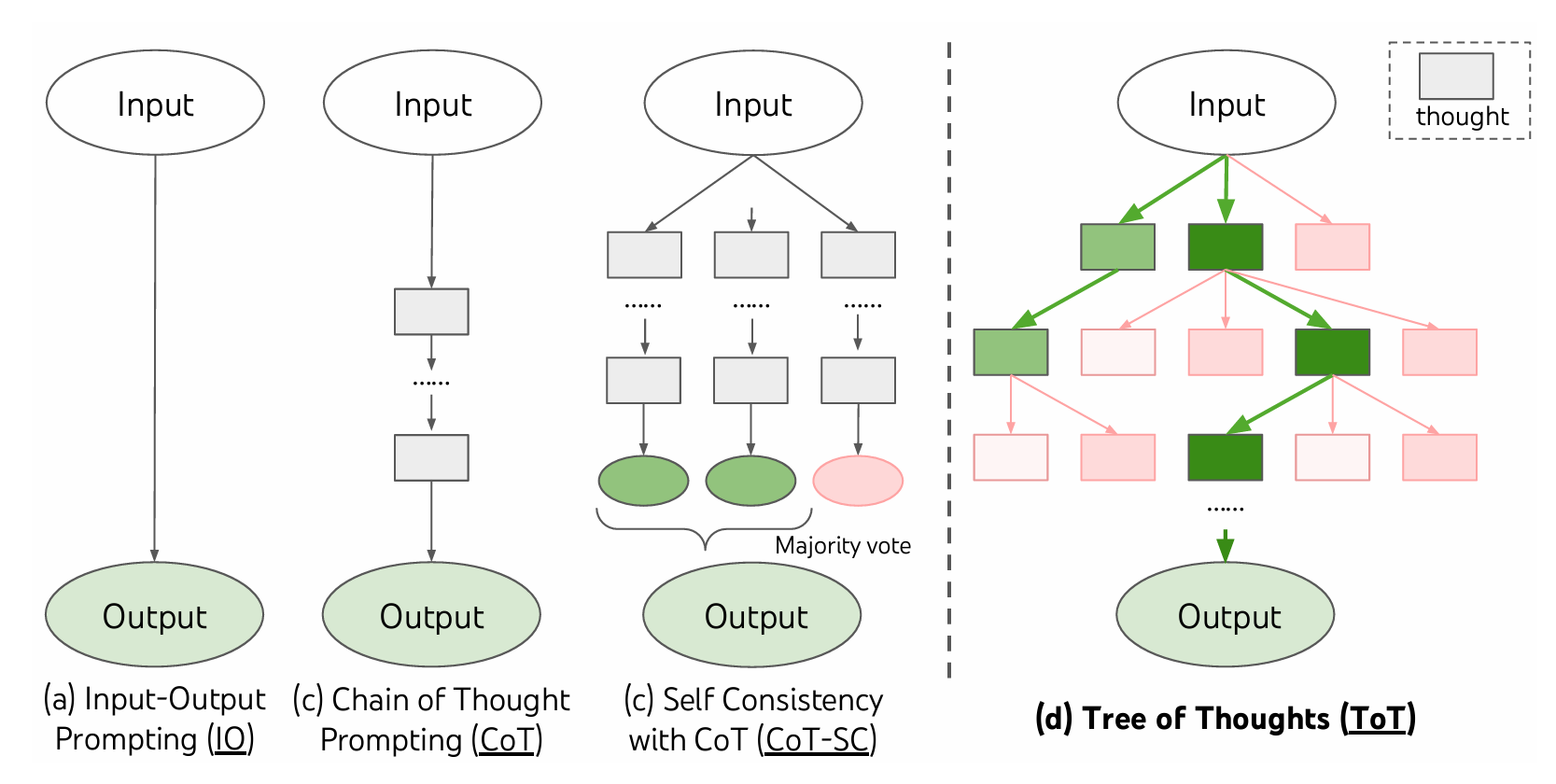
CoT(Chain-of-Thought)는 “단계 별로 설명해줘”와 같은 말을 프롬프트를 함께 입력하는 것으로 언어 모델이 단계별로 추론하도록 유도해 문제 해결 능력을 향상시키는 프롬프팅 기법이다. 이는 transformer 기반 모델이 출력을 다시 입력으로 사용하는 식으로(autoregressive) 동작하기 때문에 유효하다. 즉, 출력 토큰을 다시 입력으로 사용하므로 sequence의 앞쪽에서 출력한 결과의 품질이 이후 출력 결과에 영향을 주는 것이다.
이런 CoT는 하나의 추론 경로만 사용하는 선형 CoT와, 여러 추론 경로를 탐색하는 비선형 CoT로 나뉠 수 있다. 비선형 CoT 중 ToT에 대해 더 알아보자.
ToT(Tree-of-Thought)란?
ToT(Tree-of-Thought)(NeurlPS 2023)는 비선형 CoT 기법의 하나로, 하나의 추론 경로만 활용하는 대신 추론 중간에 분기(branch)하여 트리 구조로 여러 추론 경로를 동시에 탐색하고 평가하여 최적의 답을 도출한다.
ToTRM
ToTRM 개요
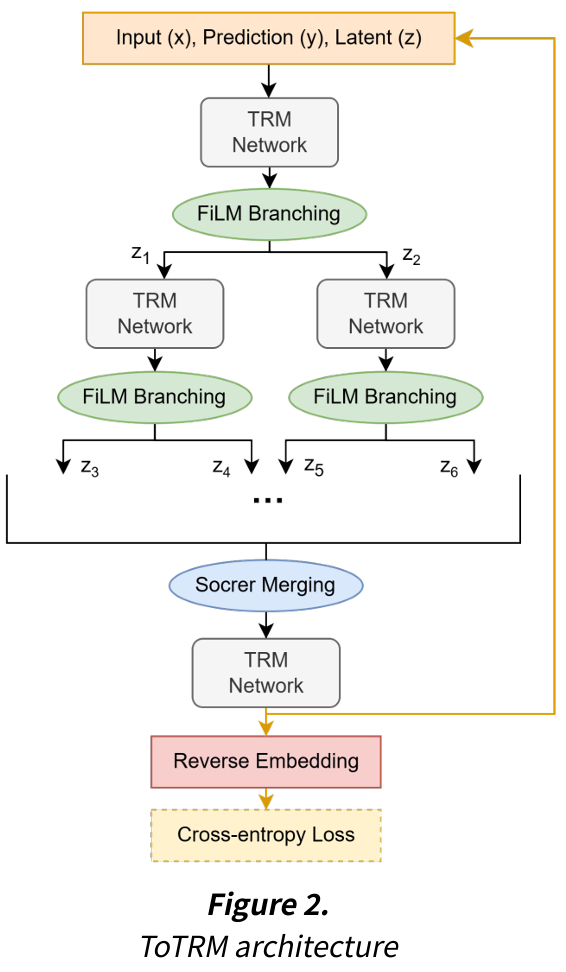
ToTRM(Tree-of-Thought Tiny Recursive Model)은 TRM에 ToT의 아이디어를 적용하여, TRM의 선형적 추론을 트리 구조로 확장한 모델이다. 즉, LLM에서 사용하는 ToT를 아키텍처(layer) 레벨에서 구현하여, 작은 모델로도 복잡한 추론 경로를 탐색할 수 있게 한다.
ToTRM의 method는 branching과 merging으로 나누어 볼 수 있다. ToTRM은 이런 아키텍처로 layer 수준의 ToT를 구현하여 병렬적으로 다양한 추론 경로를 탐색하고 가장 좋은 경로를 선택한다.
Branching(분기): branch하는 횟수를 branching step이라고 한다. branching step번의 L_cycle에서 각 z_L을 2개로 복사하여 이진 트리 형태로 branch한다. 즉, Tree width는 $2^{\text{branching steps}}$만큼 증가한다. (ex. 3번 분기하면 8개의 branch가 생성된다.)
Merging(병합): 모든 L_cycle 완료 후 $2^n$개의 branch를 하나로 merge한다. 최종적으로 하나의 y가 계산된다.
ToTRM은 pretrained TRM에 ToTRM method에 따른 component를 추가한 뒤, TRM은 fine-tuning하고 component들은 pretrain하는 것으로 학습시킨다.
Branch Method
z에 대한 단순 복사 대신, FiLM(Feature-wise Linear Modulation) method를 각 branch를 차별화하며 분기하는 branch method로 사용했다. 즉, branching을 할 때마다 FiLM 연산으로 새로운 branch를 생성했다.
branching 시에 원본 embedding 값을 단순 복사하는 경우 각 branch의 추론에 차이가 없으므로 의미가 없고, FiLM 대신 학습 가능한 벡터를 하나 둬서 embedding에 더하는 것으로도 구현해봤었는데, branch 간 코사인 유사도가 0.8 정도로 높게 나왔었다.
FiLM (Feature-wise Linear Modulation)
FILM(Feature-wise Linear Modulation)(AAAI 2018)은 신경망 내의 중간 feature map을 conditioning하는 기법으로, VQA나 style transfer 등에서 사용된다.
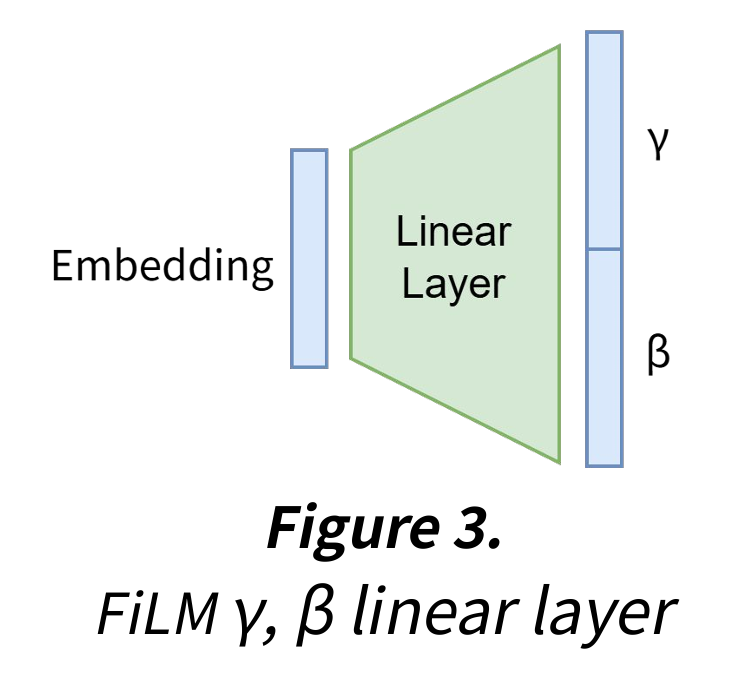
FiLM 공식: z_out = γ ⊙ z + β
- γ: 1.0 근처에서 시작, 각 feature에 대한 scale을 수행하는 scalar이다. (곱셈)
- β: 0 근처에서 시작, 각 feature에 대한 shift를 수행하는 scalar이다. (덧셈)
- γ와 β를 embedding에 element-wise하게 연산한다.
embedding_length x embedding_length * 2 만큼의 linear layer을 사용해 각 embedding에 대한 γ(scale)와 β(shift) 값을 구했다. 이후 FiLM 연산을 수행해 한 branching 이후에 생성되는 두 branch의 각 embedding이 적절히 달라지게 했다.
Diversity Loss & Branch Loss
각 branch가 서로 다른 예측을 하도록 diversity loss를 사용했고, 각 branch가 정답을 예측하도록 branch loss를 사용했다.
Diversity loss는 각 branch의 z 끼리의 cosine similarity를 계산하고, hyperparameter로 지정한 margin과의 차이를 loss로 한 것이다. 모든 branch가 같은 해로 수렴하는 문제를 방지하고, 다양한 추론 경로 탐색 유도한다.
- Branch loss는 merge 전에 각 branch가 예측한 결과와 ground truth 간의 cross entropy를 계산한 loss이다. 각 branch가 최대한 정답을 예측하도록 한다.
Merge Method
Scorer를 사용해 각 branch에 대한 score를 계산하고, score에 따라 전체 branch에 대한 가중평균으로 branch를 합치는 merge method를 사용했다. 이를 통해 각 branch이 담고 있는 정보를 적절히 합쳤다.
이외에도 mean, max, learned_weighted 등의 method를 사용해봤지만, scorer를 사용하는 방법이 가장 논리적으로 적절하다고 판단했고, 실제로 성능이 제일 좋았다.
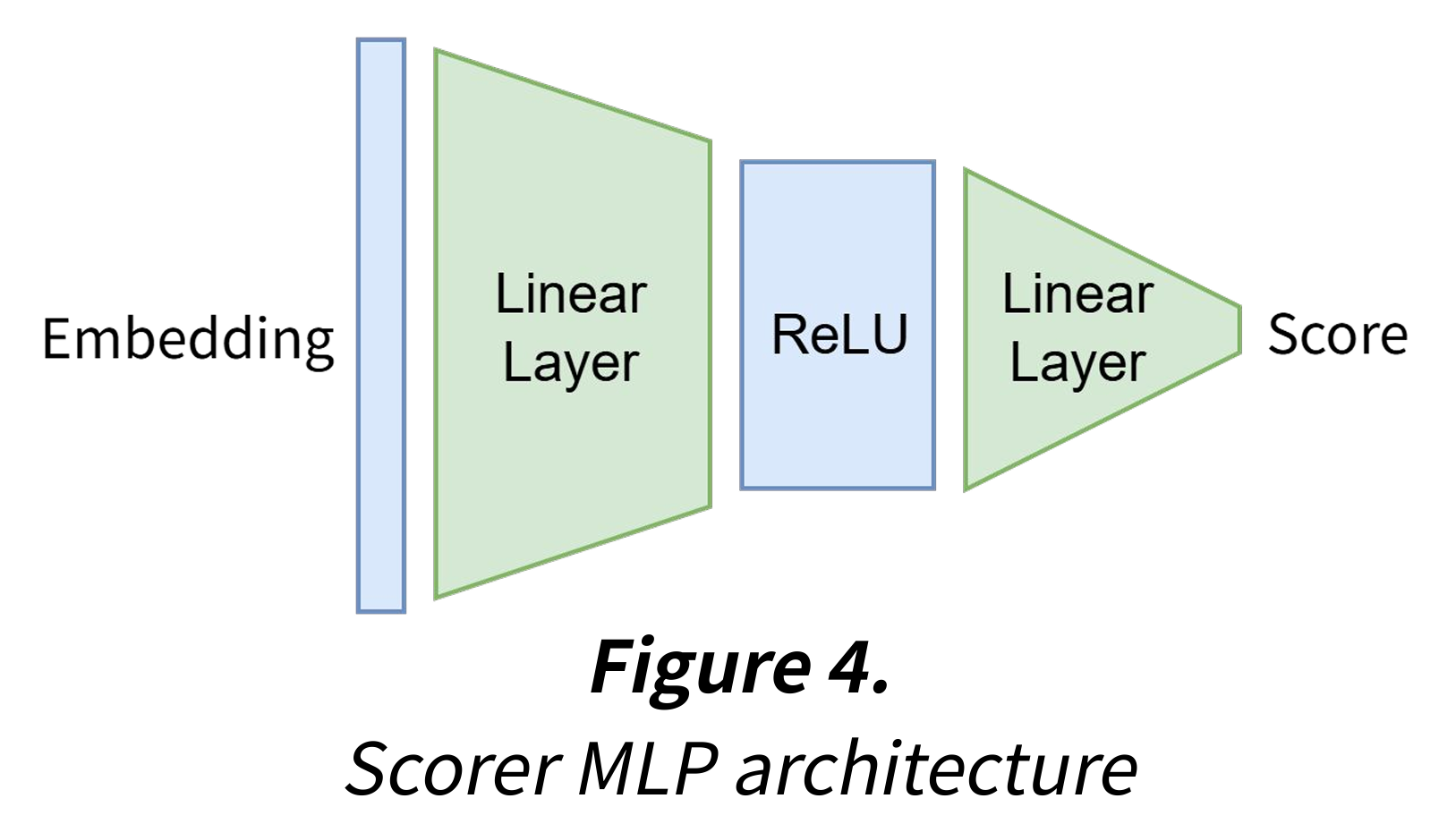
Scorer
Scorer는 작은 MLP로, 각 embedding을 입력으로 받아 중요도를 나타내는 score 값 하나를 출력한다. scorer를 사용한 token level scoring, branch level scoring으로 merge를 수행한다.
- Token Level Scoring: 각 branch에는 sequence length만큼의 embedding(token)이 존재하므로, 하나의 branch의 각 embedding들에 대해 score를 계산해 가중합하여 해당 branch에 대한 정보를 담고 있는 하나의 branch embedding을 도출한다.
- Branch Level Scoring: branch 별로 존재하는 branch embedding에 대해 score를 계산하고, 해당 값으로 전체 embedding에 대해 가중합하여 branch를 합친다.
Scorer Loss
Scorer가 branch를 잘 선택하도록 각 branch의 실제 accuracy와 scorer의 예측 score에 대한 cross entropy를 한 scorer loss를 사용했다. 이는 Scorer가 실제로 좋은 branch를 선택하도록 한다.
Results
RTX 4090에서 다음 조건으로 학습을 수행했다.
- 데이터셋: Sudoku Extreme (train 1,001,000개, test 2,113개)
- Base 모델: TRM (H_cycles=3, L_cycles=6, hidden_size=512)
- Branching steps: 3 (8개 branch)
- 학습: 14000 epochs, eval every 500 epochs
- Batch size: 128
- ToTRM Learning rate: 1e-4
- TRM Learning rate: 1e-5
Accuracy
다음과 같이 ablation study를 하며 accuracy를 찍어봤고, ToTRM이 sudoku extreme에서 TRM에 비해 5%p 정도의 accuracy 향상을 보였다. 또한 FiLM, scorer, 새로 추가한 loss들의 유의미함을 확인했다.

Model Size
ToTRM은 TRM에 추가 파라미터를 사용하여 TRM에 비해 model size가 약간 증가했지만, LLM에 비하면 아주 작은 수준이다. 또한 추가 파라미터는 725,378(0.73M)개로, ToTRM 전체의 9% 수준이다.
TRM: 6.83M (6,829,058)
ToTRM: 7.55M (7,554,436)
GPT-OSS: 120B
Deepseek R1: 671B
Latency
ToTRM, TRM 각각 10개의 샘플에 대해 latency를 측정해 평균낸 결과, ToTRM은 sudoku 샘플 하나당 173ms, TRM은 sudoku 샘플 하나당 133ms의 latency를 확인했다. 마찬가지로 ToTRM이 TRM에 비해 증가했지만, LLM에 비하면 여전히 아주 작은 수치이다.
Conclusion
ToTRM의 의의
- ToTRM은 TRM에 LLM CoT 기법인 ToT를 적절히 적용하였고, 9% 정도의 model size 증가로 sudoku extreme에 대해 accuacy를 5%p 가량 향상시켰다.
- 이를 통해 작은 모델로도 복잡한 다중 경로 추론이 가능함을 보였다. 즉, LLM의 거대한 크기와 비용 없이도, 특정 task에 대해서 추론 능력을 향상시킬 수 있는 아키텍처적 접근의 가능성을 제시한다.
향후 연구 방향
다음과 같은 향후 연구 방향이 있다.
- Branch 중간에 merge 추가하는 등 Graph-of-Thought로 확장을 시도할 수 있다.
- TRM에서는 sudoku extreme 외에도 ARC-AGI 1, 2에 대해 성능을 보였는데, 해당 벤치마크에 대해서도 실험해볼 수 있다.
- LLM task 등 다른 task에도 시도해볼 수 있다.